背景 #
Cloudflare的机器学习检测在保障网络安全和完整性方面起着关键作用,每秒处理超过4600万个HTTP请求,峰值时可达到超过6300万个请求。机器学习模型推理是系统延迟的一个组成部分,需要从请求中提取和准备特征,并通过CatBoost模型生成检测结果。
原先的设计使用Gagarin作为Go语言的特征服务平台,通过Unix域套接字提供机器学习特征。然而,随着特征数量和请求量的增加,缓存命中率下降,导致延迟增加。在高峰时段,延迟进一步恶化,导致性能不佳、资源利用率低下以及机器学习特征的可用性下降。
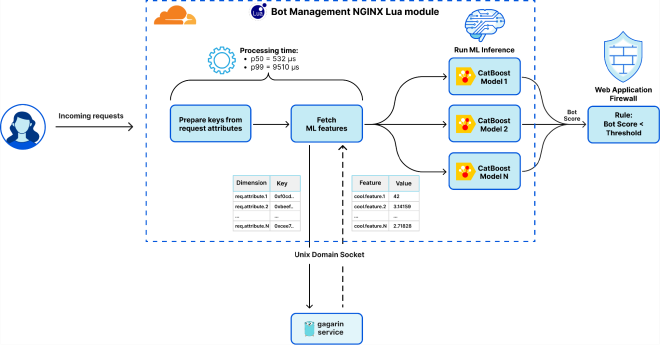
为了改进系统性能,他们探索了多种解决方案,包括优化现有的Gagarin平台、考虑使用Quicksilver、增加多层缓存、对Unix套接字进行分片,以及切换到RPC等。
但尝试的这些方案都面临一些问题
-
高尾延迟:系统在高峰期遇到了尾延迟增加的问题,这是由于Unix套接字上的CPU争用和Lua垃圾收集器引起的。
-
资源利用率不佳:系统的CPU和内存利用率没有被充分优化,导致在服务器上运行其他服务时剩余资源有限。
-
机器学习特征的可用性下降:由于memcached超时,机器学习特征的可用性下降,从而增加了一部分请求的误报或漏报的可能性。
-
可扩展性限制:随着添加更多的机器学习特征,系统接近了可扩展性的极限。
采用基于第一性原则的设计方法,他们提出了一个问题:“操作系统提供的最有效的低级数据传输方法是什么?” 他们使用 ipc-bench 评估了 Linux 生态系统中各种 IPC 通信的性能基准,测量方式是通过在两个进程之间发送 ping-pong 消息
| IPC method | Avg duration, μs | Avg throughput, msg/s |
|---|---|---|
| eventfd (bi-directional) | 9.456 | 105,533 |
| TCP sockets | 8.74 | 114,143 |
| Unix domain sockets | 5.609 | 177,573 |
| FIFOs (named pipes) | 5.432 | 183,388 |
| Pipe | 4.733 | 210,369 |
| Message Queue | 4.396 | 226,421 |
| Unix Signals | 2.45 | 404,844 |
| Shared Memory | 0.598 | 1,616,014 |
| Memory-Mapped Files | 0.503 | 1,908,613 |
根据评估,他们发现Unix套接字虽然可以处理同步问题,但不是最快的IPC方法。最快的IPC机制是共享内存和内存映射文件。这两种方法具有类似的性能,前者使用特定的tmpfs卷在/dev/shm中,利用专门的系统调用,而后者可以存储在任何卷中,包括tmpfs或HDD/SDD。
mmap 并没有提供像 unix 套接字那样提供数据同步功能,因此面临几个关键问题
- 特征获取和更新:需要有效地从文件中获取和更新数百个浮点特征数组,这在处理文件数据时是一个挑战。
- 数据同步和并发更新:由于多个进程同时访问数据,他们需要确保安全、并发且频繁的更新操作。
- CPU争用:需要解决之前在Unix套接字上遇到的CPU争用问题,以改善性能。
- 可扩展性和未来增加特征的支持:需要确保系统能够有效地支持将来更多的维度和特征的添加,以满足不断增长的需求。
根据以上问题,对 mmap 做了一些增强
- wait-free, 参考 Linux RCU 和 left-right
- zero-copy 序列化,使用 rkyv
最终 cloudflare 开发出了 mmap-sync 这个库,并将其开源。
使用 mmap-sync 之后,整个系统架构进行了重构
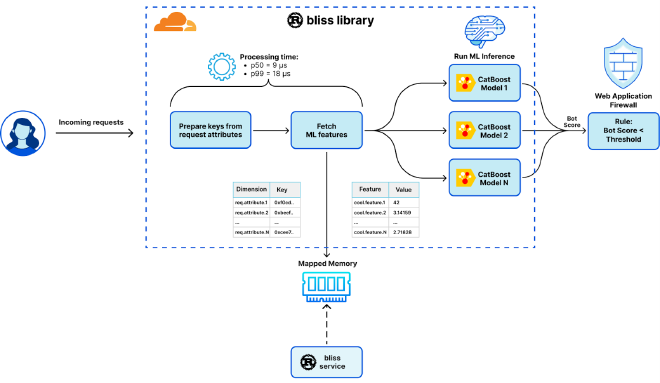
- bliss 使用 rust 实现,作为 sidecar 运行,为大数据量和高 I/O 操作进行批处理设计,使用 tokio
- bliss lib 使用 mmap-sync 获取机器学习特征数据,还进行了一些增强
- 预分配数据结构,整个运行时无 alloc
- SIMD 优化
- 编译器参数调优
[profile.release] codegen-units = 1 debug = true lto = "fat" opt-level = 3
优化之后的数据对比
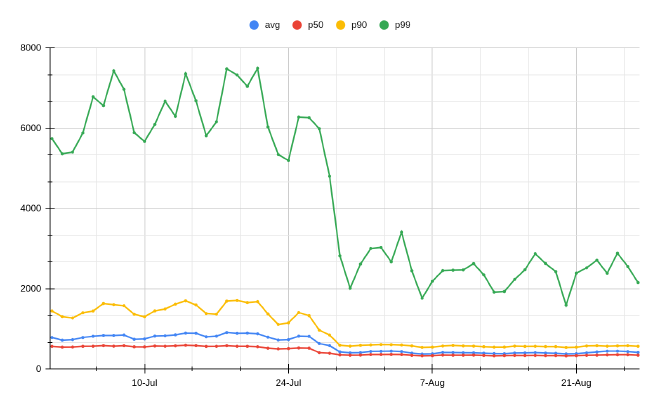
机器学习特征提取延迟减少了几个数量级
| Latency metric | Before (μs) | After (μs) | Change |
|---|---|---|---|
| p50 | 532 | 9 | -98.30% or x59 |
| p99 | 9510 | 18 | -99.81% or x528 |
| p999 | 16000 | 29 | -99.82% or x551 |
left-right 基础 #
- left-right 提出了一种新颖的并发控制机制
- 单个 writer 多个 reader
- reader 是 wait- free 的, 且不需要 gc
- reader 可以任意数量扩展,对并发读友好
- writer 需要 lock
结构 #
- left-right 要求保留两个数据副本, 称为 left_instance 和 right_instance.
- 读和写在不同的 instance 上执行, 并使用 version 定序.
- version 取值只有 0 和 1.
- left-right 使用一个二维数组
read_indicator[][]为每个 reader 记录 version.
+----------------+
| left_right |
+----------------+
|
left | right
+------------+-------------+
| |
v v
+-----------------+ +-----------------+
| left_instance | | right_instance |
+-----------------+ +-----------------+
+----------------------+----------------------+
| read_indicator[0][0] | read_indicator[1][0] |-------> thread_id = 0
+----------------------+----------------------+
| read_indicator[0][1] | read_indicator[1][1] |
+----------------------+----------------------+
| read_indicator[0][2] | read_indicator[1][2] |
+----------------------+----------------------+
| read_indicator[0][3] | read_indicator[1][3] |
+----------------------+----------------------+
^ ^
0 | | 1
+----------+-----------+
|
|
+-----------------+
| version_index |
+-----------------+
算法 #
reader 通过 containts() 读取
- 读是 wait-free 的
- 首先读取
versionIndex的值,versionIndex是一个原子变量,取值为 0 或 1 arrive()设置当前 reader 使用versionIndex- 根据
versionIndex的指示读取 left 或者 right 实例 depart()设置 reader 离开versionIndex

arrive() 设置 version, depart

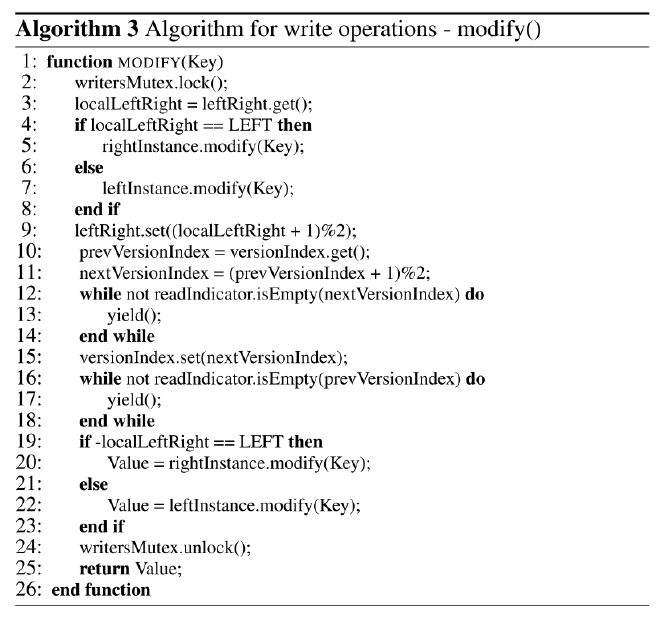
writer 通过 modify() 修改
- 写需要 lock 保护,但是这个 lock 不一定是 mutex,可以是其他实现,这意味着 writer 可以进一步优化为 lock-free 或者 wait-free 的
- writer 首先读取 left_right 指向的实例,并左右切换:如果是 left_instance,则修改 right_instance
- 发布
versionIndex变量,如果被 reader 持有,需要等待
算法可以证明对于任意数量的线程总是 wait-free 的
- 算法1 指出读取操作没有循环等待,总是在常熟步骤完成,因此可以保证读是 wait-free 的
- 对于写操作有一个循环,writer 需要等待上一个 reader 的进度,但由于 reader 是 wait-free 的,所以 reader 不会饿死 writer
- 对于写操作,还需要一个 lock,这意味着写-写可能会饥饿,但这不在 left-right 的保证之内,同时如果 writer 的 lock 是 wait-free 的,则意味着 writer 在整体是 wait-free 的
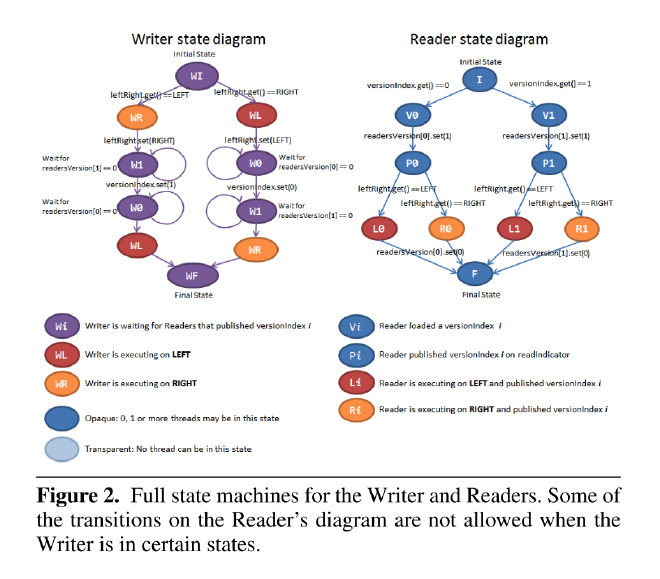
left-right 内存顺序是可线性化的, 通过以上算法, 直觉上也很容易推理. 论文将单个 writer 多个 reader 建模为一个全状态的状态机进行的证明》
实现 #
结构 #
-
Synchronizer是 mmap-sync 的接口,提供 mmap 读写,内部由StateContainer和DataCotainer组成StateContainer包含一个 mmap 文件,记录State运行时会解释为StateState布局遵循 left-right 的结构,包括一个 version 原子变量和一组 left-right reader- reader 并没有使用线程 id,使用原子变量表示多少个 reader,读取是递增,读取结束递减
DataContainer遵循 left-right ,包括 version 和 left-right 两个 mmap read-only实例文件
-
InstanceVersion就是 left-right 的 versionIndex, 不过编码上做了一些改动: 64-bit 无符号整数表示,idx (0 OR 1) | data size (<549GB) | checksum/// `InstanceVersion` represents data instance and consists of the following components: /// - data idx (0 or 1) - 1 bit /// - data size (<549 GB) - 39 bits /// - data checksum - 24 bits #[derive(Clone, Copy, Debug, PartialEq)] pub(crate) struct InstanceVersion(u64); const DATA_SIZE_BITS: usize = 39; const DATA_CHECKSUM_BITS: usize = 24;
write #
写入过程遵循 left-right 算法, 略微不同的是增加了 writer 等待 reader 释放版本时的 timeout 限制
- 序列化数据
- 获取或新建
state - 获取下一个版本
- 在新版本的实例上写入数据,然后切换版本
// vim src/synchronizer.rs + 73
/// Writes a given `entity` into the next available data file.
///
/// Returns the number of bytes written to the data file and a boolean flag, for diagnostic
/// purposes, indicating whether the reader counter was reset due to a reader exiting without
/// decrementing it.
///
/// # Parameters
/// - `entity`: The entity to be written to the data file.
/// - `grace_duration`: The maximum period to wait for readers to finish before resetting the
/// reader count to 0. This handles scenarios where a reader process has
/// crashed or exited abnormally, failing to decrement the reader count.
/// After the `grace_duration` has elapsed, if there are still active
/// readers, the reader count is reset to 0 to restore synchronization state.
///
/// # Returns
/// A result containing a tuple of the number of bytes written and a boolean indicating whether
/// the reader count was reset, or a `SynchronizerError` if the operation fails.
pub fn write<T>(
&mut self,
entity: &T,
grace_duration: Duration,
) -> Result<(usize, bool), SynchronizerError>
where
T: Serialize<DefaultSerializer>,
T::Archived: for<'b> CheckBytes<DefaultValidator<'b>>,
{
// serialize given entity into bytes
let mut serializer = DefaultSerializer::default();
let _ = serializer
.serialize_value(entity)
.map_err(|_| FailedEntityWrite)?;
let data = serializer.into_serializer().into_inner();
// ensure that serialized bytes can be deserialized back to `T` struct successfully
check_archived_root::<T>(&data).map_err(|_| FailedEntityRead)?;
// fetch current state from mapped memory
let state = self.state_container.state(true)?;
// calculate data checksum
let mut hasher = SeaHasher::new();
hasher.write(&data);
let checksum = hasher.finish();
// acquire next available data file idx and write data to it
let (new_idx, reset) = state.acquire_next_idx(grace_duration);
let new_version = InstanceVersion::new(new_idx, data.len(), checksum)?;
let size = self.data_container.write(&data, new_version)?;
// switch readers to new version
state.switch_version(new_version);
Ok((size, reset))
}
State 保存在 mmap 文件中,调用 state() 方法将其解释为 State,如果文件不存在则初始化
// vim src/state.rs +117
/// Fetch state from existing memory mapped file or create new one
#[inline]
pub(crate) fn state(&mut self, create: bool) -> Result<&mut State, SynchronizerError> {
if self.mmap.is_none() {
let state_file = OpenOptions::new()
.read(true)
.write(true)
.create(create)
.mode(0o660) // set file mode to allow read/write from owner/group only
.open(&self.state_path)
.map_err(FailedStateRead)?;
let mut need_init = false;
// Reset state file size to match exactly `STATE_SIZE`
if state_file.metadata().map_err(FailedStateRead)?.len() as usize != STATE_SIZE {
state_file
.set_len(STATE_SIZE as u64)
.map_err(FailedStateRead)?;
need_init = true;
}
let mut mmap = unsafe { MmapMut::map_mut(&state_file).map_err(FailedStateRead)? };
if need_init {
// Create new state and write it to mapped memory
let new_state = State::default();
unsafe {
mmap.as_mut_ptr()
.copy_from((&new_state as *const State) as *const u8, STATE_SIZE)
};
};
self.mmap = Some(mmap);
}
Ok(unsafe { &mut *(self.mmap.as_ref().unwrap().as_ptr() as *mut State) })
}
acquire_next_id 获取下一个要写入的版本 next_idx, 然后等待该版本上的所有 reader 释放, 如果超时则退出
// vim src/state.rs +45
/// Acquire next `idx` of the state for writing
#[inline]
pub(crate) fn acquire_next_idx(&self, grace_duration: Duration) -> (usize, bool) {
// calculate `next_idx` to acquire, in case of uninitialized version use 0
let next_idx = match InstanceVersion::try_from(self.version.load(Ordering::SeqCst)) {
Ok(version) => (version.idx() + 1) % 2,
Err(_) => 0,
};
// check number of readers using `next_idx`
let num_readers = &self.idx_readers[next_idx];
// wait until either no more readers left for `next_idx` or grace period has expired
let grace_expiring_at = Instant::now().add(grace_duration);
let mut reset = false;
while num_readers.load(Ordering::SeqCst) > 0 {
// we should reach here only when one of the readers dies without decrement
if Instant::now().gt(&grace_expiring_at) {
// reset number of readers after expired grace period
num_readers.store(0, Ordering::SeqCst);
reset = true;
break;
} else {
thread::sleep(SLEEP_DURATION);
}
}
(next_idx, reset)
}
data_container write 写入数据,根据 version 选择写入哪个 mmap 文件
// vim src/data.rs +24
/// Write `data` into mapped data file with given `version`
pub(crate) fn write(
&mut self,
data: &[u8],
version: InstanceVersion,
) -> Result<usize, SynchronizerError> {
let data_file = OpenOptions::new()
.read(true)
.write(true)
.create(true)
.mode(0o640) // set file mode to allow read/write from owner, read from group only
.open(version.path(&self.base_path))
.map_err(FailedDataWrite)?;
// grow data file when its current length exceeded
let data_len = data.len() as u64;
if data_len > data_file.metadata().map_err(FailedDataWrite)?.len() {
data_file.set_len(data_len).map_err(FailedDataWrite)?;
}
// copy data to mapped file and ensure it's been flushed
let mut mmap = unsafe { MmapMut::map_mut(&data_file).map_err(FailedDataWrite)? };
mmap[..data.len()].copy_from_slice(data);
mmap.flush().map_err(FailedDataWrite)?;
Ok(data.len())
}
read #
read 遵循 left-right 算法
- 获取要读取的版本
- 递增当前版本的 reader 数量
- 读取数据进行 zero-copy 的序列化
- 返回 guard,RAII 手法,析构时会递减这个版本的 reader
// vim src/synchronizer.rs +159
/// Reads and returns an `entity` struct from mapped memory wrapped in `ReadGuard`.
///
/// # Safety
///
/// This method is marked as unsafe due to the potential for memory corruption if the returned
/// result is used beyond the `grace_duration` set in the `write` method. The caller must ensure
/// the `ReadGuard` (and any references derived from it) are dropped before this time period
/// elapses to ensure safe operation.
///
/// Additionally, the use of `unsafe` here is related to the internal use of the
/// `rkyv::archived_root` function, which has its own safety considerations. Particularly, it
/// assumes the byte slice provided to it accurately represents an archived object, and that the
/// root of the object is stored at the end of the slice.
pub unsafe fn read<T>(&mut self) -> Result<ReadResult<T>, SynchronizerError>
where
T: Archive,
T::Archived: for<'b> CheckBytes<DefaultValidator<'b>>,
{
// fetch current state from mapped memory
let state = self.state_container.state(false)?;
// fetch current version
let version = state.version()?;
// create and lock state guard for reading
let guard = ReadGuard::new(state, version)?;
// fetch data for current version from mapped memory
let (data, switched) = self.data_container.data(version)?;
// fetch entity from data using zero-copy deserialization
let entity = archived_root::<T>(data);
Ok(ReadResult::new(guard, entity, switched))
}
version 读取 state 的版本
// vim src/state.rs +33
/// Return state's current instance version
#[inline]
pub(crate) fn version(&self) -> Result<InstanceVersion, SynchronizerError> {
self.version.load(Ordering::SeqCst).try_into()
}
ReadGuard 持有当前读取数据的版本,构造时递增 reader 数量,析构时递减版本上的 reader 数量
// vim src/guard.rs +22
/// An RAII implementation of a “scoped read lock” of a `State`
pub(crate) struct ReadGuard<'a> {
state: &'a mut State,
version: InstanceVersion,
}
impl<'a> ReadGuard<'a> {
/// Creates new `ReadGuard` with specified parameters
pub(crate) fn new(
state: &'a mut State,
version: InstanceVersion,
) -> Result<Self, SynchronizerError> {
state.rlock(version);
Ok(ReadGuard { version, state })
}
}
// vim src/state.rs +39
/// Locks given `version` of the state for reading
#[inline]
pub(crate) fn rlock(&mut self, version: InstanceVersion) {
self.idx_readers[version.idx()].fetch_add(1, Ordering::SeqCst);
}
// vim src/state.rs +75
/// Unlocks given `version` from reading
#[inline]
pub(crate) fn runlock(&mut self, version: InstanceVersion) {
self.idx_readers[version.idx()].fetch_sub(1, Ordering::SeqCst);
}