CURP 概述 #
我们所熟知的非拜占庭故障的复制协议如 paxos,raft 完成一次复制需要两个 RTT:第一个 RTT 用于定序,第二个 RTT 则用来复制进行持久化。这篇论文提出了一个新的复制协议 CURP(Consistent Unordered Replication Protocol),只要操作是可交换的,不再需要定序的 RTT,只需要一个复制 RTT 就可以完成。
容错系统依赖复制,在数据中心中,基于复制的系统延迟会增加一倍,在 geo 场景中,这个延迟还会继续放大。如果操作和复制可以重叠执行,那么可以消除这个延迟。但实践中往往不可行,原因在于执行一个操作并复制到其他副本时需要确定顺序,如果不这样做,当服务崩溃后乱序的操作会导致副本之间数据不一致。所以,像 raft 中会通过 leader 确定操作的顺序后在复制到 follower,而 paxos 即使没有 leader,也会存在一个阶段确定顺序。
论文利用操作如果是可交换的,那么执行顺序不重要的事实提出了 CURP 协议。客户端向多个 witness 副本 + primary 副本发送请求,primary + witness 回复后完成,整个过程只需要 1 个 RTT,但如果操作不可交换,还需要两 2 个 RTT。如果 primary崩溃,witness 信息和普通副本信息结合后可以恢复出一致的状态。
CURP 可以和现有的主备或者其他复制协议一起工作。
CURP 协议思路 #
目前的复制协议都离不开两个步骤
- 为并发客户端请求确定操作顺序
- 将请求复制到备份服务器上
CURP 核心思想是将排序和持久化分开,在操作可交换的前提下复制只需要 1 RTT。
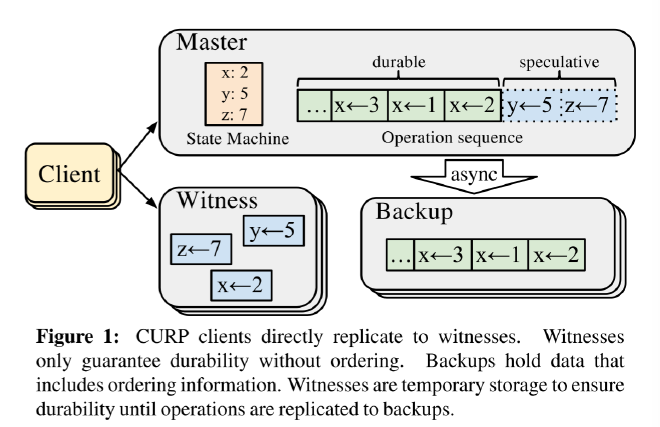
CURP 使用见证者(witness)来临时存储客户端的请求,见证者不会对请求进行排序,如图1。客户端并行的向 witness + master 发送请求,只需要1个 RTT 就完成复制。之后,master 异步的将请求复制到backup。
在 master 中存在两类操作序列
- durable 是已经复制到 backup 的操作
- speculative 是已经被 witness + master 接收的操作
上面的想法需要处理两个问题
问题1:
master 崩溃恢复后,需要从 witness 重放操作,但由于 witness 不排序,如果直接应用 witness 的记录回导致不一致。
CURP 通过 witness 判断操作是否可交换来解决这个问题:witness 只接收可交换的操作,如果操作不可交换,客户端需要请求 master 进行同步,同步会将 master 上的 speculative 的序列一起同步(可以看作 batch)。
所以,如果操作可交换,复制仅需 1 RTT(fast path),否则进行同步需要 2 RTT(slow path)。
问题2:
我们知道 master 重启时会从 witness 重放进行恢复,但在崩溃前,master 可能已经将 witness 上的操作复制到其他 backup了,所以 master 可能会重复执行这些命令。
解决这个问题需要检测和过滤重复执行,这CURP 使用 RIFL。重复不光是 CURP 会面临的问题,其他复制协议也会存在。
CURP 协议 #
架构模型 #
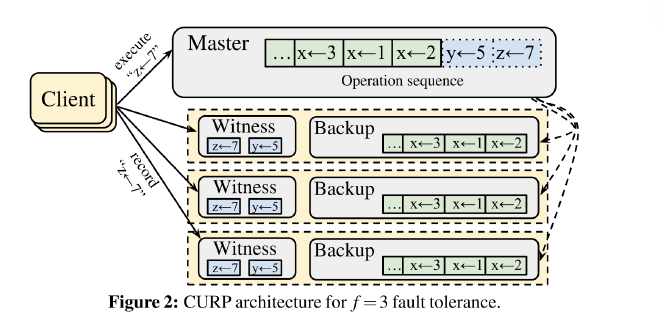
CURP 和其他复制协议一样, 采用 f + 1 个节点, 其中 f 个 backup, 1 个 master, 此外 CURP 还需要 f 个 witness 节点, witness 可以和 backup 部署在一起, 也可以单独部署, witness 不会影响 backup.
CURP 不会更改现有复制协议的运行机制 (🤔 但不意味着实现 CURP 不需要修改原复制协议的代码). CURP 对网络没有任何假设, 可以运行在任何网络环境, 可以运行在 geo 分布的广域网环境, 而像 Speculative Paxos 和 Network-Order Paxos 则不可以.
客户端 #
客户端发送 RPC 请求到 master, 如果不能接收响应则重试, 如果 master 崩溃, 客户端尝试其他节点.
客户端发送并发到发送请求到 master + witness, 然后客户端等待 witness + master 响应, 如果 witness + master 都接收请求则复制在 1 个 RTT 内完成.
客户端必须等待 f 个 witness 返回响应才继续下一个操作, 因为 witness 之间都是独立运行的, 客户端的消息会以任意的顺序到达 witness, 这可能导致某些 witness 接收, 某些 witness 拒绝, 因此必须要等待所有 witness, 但在恢复期间仅使用一个 witness.
如果 witness 拒绝, 客户端需要向 master 发送 sync RPC, sync RPC 会让 master 将请求复制到其他节点, 这种情况会导致复制在 2 个 RTT 内完成.
在最坏的情况下, 客户端的请求先到达 master 并响应, 其中某个 witness 拒绝, 客户端需要再次像 master 发送 SYNC RPC, 这样就需要 3 个 RTT.
Witness #
witness 需要支持 3 个基本的操作
- 记录客户端的操作
- 在 master 通知删除时可以删除记录的操作
- 在恢复期间为 master 提供保存的操作记录
要支持这 3 个操作, witness 需要持久化记录, 由于 witness 被设计为临时存储, 因此只需要少量的空间, 通常 flash 或者更低延迟的 RAWCloud 成本都能接受.
witness 的核心是判断操作请求是否可交换, 对于简单的 kv 系统, 可以利用不同 key 可交换的属性, 例如 witness 存储了 x ← 1, 那么 x ←5 的这个操作就不具备可交换性.
但对于更加复杂的系统, 如何判断操作是否可交换是困难的, 例如数据库更新 SQL PDATE T SET rate = 40 WHERE level = 3 和 UPDATE T SET rate = rate + 10 WHERE dept = SDE 这种依赖系统状态的操作很难判断是否可交换, 需要应用层做更多的设计.
Master #
Master 提供排序,执行,和复制。CURP 中的 master 可以在复制到 backup 之前响应客户端,因此在 master 上存在未同步的操作,如图3。
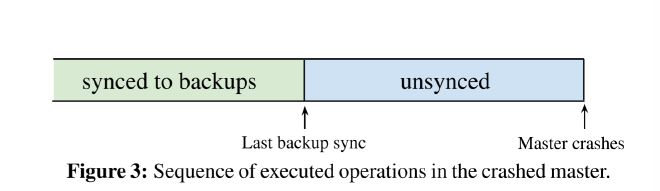
如果客户端发送到 master 的请求与 master 上 unsynced 部分的操作不可交换,master 必须执行同步。如果不这样做,可能会产生不一致。例如,master 响应后,客户端崩溃没有来得及记录到 witness,这样会导致 master 的执行无效。例如,master 首先执行 W: x ← 2, 然后执行 R: x → 2 响应客户端, 如果稍后 master 崩溃,客户端读取的值就无效了。
master 强制执行同步后,会在响应给客户端的请求中标记已同步,即使客户端记录 witness 的请求被拒绝了也可以在 2 个 RTT 内完成。
另外一个思考的地方是,master 上有很多 unsynced 的操作,如果此次操作和其他操作不可交换,强制执行同步的可以是这一批 unsynced 操作。
恢复 #
CURP 恢复包含两个阶段
- 从 backup 恢复(但实际上对于 raft 这类协议是不需要的,只需要选出新的 leader 即可)
- 从 witness 重放日志
从 backup 恢复后,master 可以任意选择 f 个 witness 来重放,在此期间,master 要停止接收客户端的请求。每个 witness 记录都是可交换的,因此 master 可以以任意的顺序执行。重放完成后,新的 master 将记录同步到 backup 并重置或重新分配一组新的 witness,重放完成后,master 可以接收请求。
Master 在重放 witness 时, 一些值可能已经复制到 backup 了, master 可能会重复执行, CURP 使用 RIFL 提供精确一次(exactly-once)语义, 在 RIFL 中, 客户端为每个 RPC 分配一个 ID , 服务器保存已完成请求的ID和结果,并用来检测和响应重复的请求, 可以将请求的 ID 和结果一起复制到 backup.
垃圾回收 #
witness 作为临时存储, 应该尽快回收空间, 这样既可以减少内存使用, 也可以减少冲突的可能性. 在 CURP 中, 只要 master 持久化到 backup 后, witness 就可以丢弃. CURP 通过 master 像 witness 发送垃圾回收 RPC 实现, 每个 RPC 处理一批, 通过 RIFL 的 ID 决定丢弃哪些请求.
Witness 重配置 #
客户端总是要等待 f 个 witess 响应之后才能进行下一步, 如果某个 witness 崩溃或无响应, 那么客户端就卡住了, 因此在 CURP 中如果 witness 崩溃或者无响应, 配置服务会停用崩溃的 witness 并重新分配一个, 之后将新的 witness 列表发送给 master, master 还会将该配置复制给 backup.
但是 master 并没有像客户端推送新的 witness 列表, 实际上这可能也不现实, 可能存在大量客户端. 客户端不更新 witness 列表就意味着客户端可能像旧的 witness 发送请求, 这会违反一致性, 因为 master 在恢复期间不会使用踢掉的 witness.
为了解决这个问题, CURP 为每个 master (master 可能会切换) 维护一个 WitnessListVersion 变量, 每当配置变更该变量递增, 客户端联系配置服务获取 witness 列表同时获取该变量. 客户端的写请求附带该变量, master 可以检测客户端是否使用旧的 witness 配置.
负载均衡 #
分区出现负载不均时往往考虑进行数据迁移, 一般迁移分为两步
- 在服务期间拷贝数据到目标分区
- 停止服务, 以确保复制所有最近的操作.
为了简化对复制协议的更改, CURP 仅要求在最后一步之行前复制数据到 backup 并重新配置 witness.
迁移完成后, 客户端可能会请求旧的分区的 master 和 witness. 对于 master 可以告诉客户端新的分区. 对于 witness 操作可能记录在旧的 witness, 不过这并不影响安全属性, 因为 master 在恢复期间重放 witness 时可以拒绝非本分区的请求.
读操作 #
读请求不需要记录到 witness, 不过对于请求 master 的读操作, master 需要判断是否和 unsynced 的操作可交换, 如果不可交换, master 需要将冲突的操作同步之后才能响应读操作.
从 bakcup 进行一致性读 #
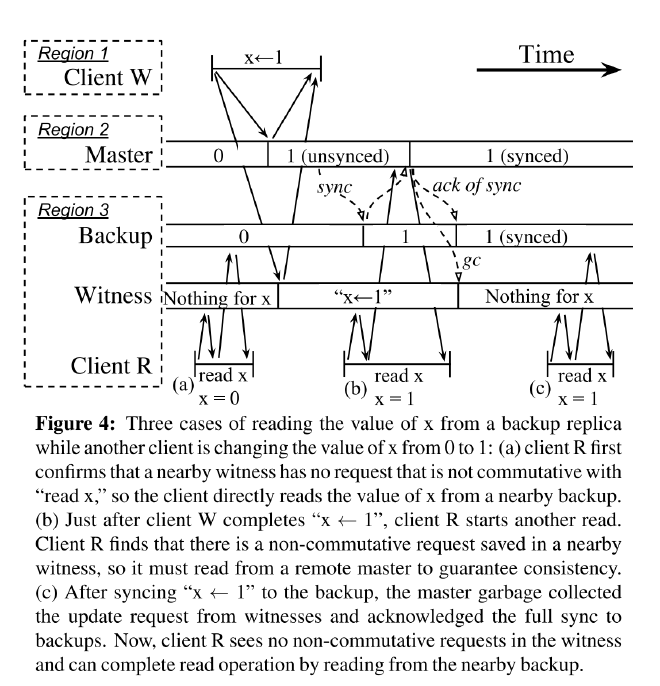
一些协议允许从 backup 读来减少 master 的压力, 在 geo 场景中, 也可以提供更好的延迟. 但是单纯的从 backup 读会导致不一致, 因为 CURP 更新可能会在同步到 backup 之前完成.
为了防止不一致, 读 backup 前需要先访问就近的 witness 询问读操作是否可以交换, 如果不可交换, 客户端需要从 master 读取. 如图 4 中, (a) 读取可交换, (b) 不可交换需要访问 master. (c) 在同步后读取可交换.
论文假设读取的值在 backup 存在, 但由于异步复制到 backup, 可能 master 存在但 backup 不存在, 所以 witness 如果不存在客户端就不需要访问 master 了, 因为两种情况
- 未同步到 backup 的, 但在 1 RTT 内同时复制到了 witness 和 master, 所以 witness 存在 master 也一定存在.
- master gc 了 witness 的值, 但 gc 前一定复制到了 bakcup, 所以 backup 一定存在.
此外 CURP 假设地下的复制协议不会在客户端读 backup 时会饭回尚未同步到其他 f 个 backup 的情况.
这个问题说的是防止读取备份副本中尚未在其他备份中完全同步的值,以 raft 来说,这个机制要求读取的 follower 不能读取已复制但还未提交的值.
CURP 工程实践 #
论文描述了在 NoSQL 系统实现 CURP 协议的实践,除此之外,datenloard 开源的 xline 分布式元数据系统也实现了 CURP。
Witness 生命周期 #

witness 分为正常模式和恢复模式, 每个模式都提供图 5 描述的 rpc 接口. witness 在收到 getRecoveryData 请求后不可逆的进入恢复模式, 恢复模式下 witness 不可变并且 witness 拒绝所有 record rpc, 恢复模式结束后, 集群配置服务可以发送 end 释放资源, 此时 witness 可以作为新的服务.
Witness 数据结构 #
将每个主键哈希为 64 位的值存储在 hash 表中, 客户端记录到 witness 的请求分两种
- 单个对象, 通过扫描哈希表看是否存在, 存在则拒绝
- 对于多对象, 首先检查这一组对象之间是可交换的, 其次在扫描哈希表
Master 检测可交换 #
Master 需要检查客户端请求的对象是否涉及 unsynced 的值, 如果涉及则不可交换, master 需要将其同步到 backup 之后才能返回给客户端.
论文提到了两种方式存储对象值的检测办法
- 如果存储在 log 中, 通过确定新的值在 log 中的位置以及上次同步的位置判断, 这里还需要和 unsynced 的 log 进行一下判断
- 对于非 log 存储的, master 为每个写操作分配一个时间戳, 同时记录上次同步的时间戳, 通过两个时间戳进行比对.
提高 master 的吞吐 #
同步的 batch 的大小在 CURP 中需要仔细考虑, 如果过大可能会增加 witness 拒绝的概率. 简单的方法是, 如果 master 有未同步的, 在响应客户端后立即进行同步.不过, 要找到最佳的 batch size,需要对系统和真实的工作负载进行测试.
垃圾回收 #
master 同步后就发送图5 中的 gc 请求给 witness, gc 请求使用 keyHash 和 RIFL 分配的 rpcId.
垃圾回收可以回收掉大部分无效的记录, 但某些记录可能无法被回收, 无效的记录可能导致某些操作一直被拒绝.
为了解决这个问题, witness 每当拒绝一个记录时, 检查该记录自写入 wintess 以来 master 进行了多少次 gc, 如果到达一定次数 (例如3), witness 像 master 询问怀疑该请求是未被 gc 的请求, master 重试该请求, 可能被过滤或者同步到备份, 然后该记录会包含在 master 的下个 gc 中.