Design & Implementation #
Haystack 认为不受欢迎的(不在 CDN 和 Cache)照片是需要磁盘操作的,优化思路为:
- 大量的小文件合并为大文件(100GB),使用物理卷管理,这样元数据可以全部在内存中。
- 对于文件采用追加写,更新不支持随机写,而是覆盖。
- 使用 compaction 进行空间回收。
1. Overview #
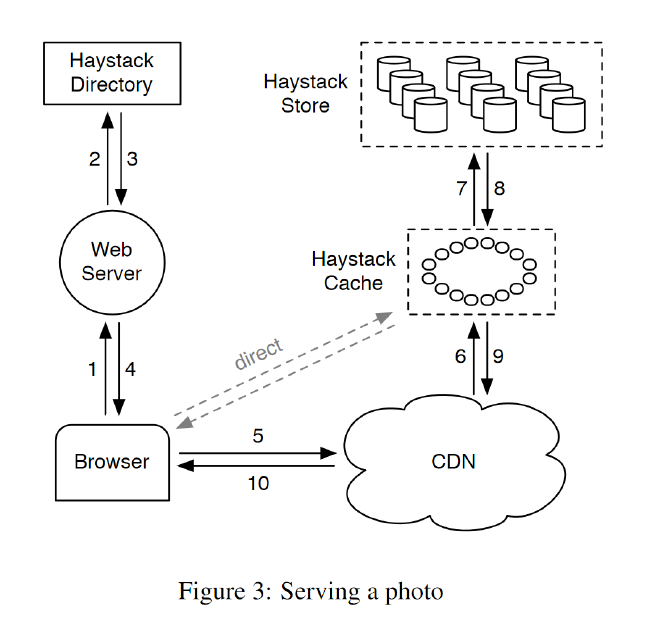
图3展示了Haystack体系结构,由3个核心组件组成:Haystack Store,Haystack Directory 和 Haystack Cache。
Haystack Store
- 封装照片存储系统,存储数据和元数据。
- 根据物理磁盘大小组织 haystack store的容量。例如,一台10tb容量的节点划分成100 个物理卷,每个卷提供100 GB 的存储。
- 物理卷会进一步分组为逻辑卷,逻辑卷是物理卷的多副本。
Haystack Directory
- 维护逻辑到物理的映射以及应用程序元数据,例如每张照片所在的逻辑卷和具有可用空间的逻辑卷。
- 类似于 GFS 的 master 或 HDFS 的namenode的作用,不过区别在于它是无状态的。
Haystack Cache
- 相当于系统内部 CDN,帮助 haystack store 缓存热点请求。

图4说明了Haystack中的写入路径。
2. Haystack Directory #
Haystack Directory 是一个相对简单的部分,信息存储在数据库中(复制的),通过 memcached 缓存。
Haystack Directory 有四个主要功能:
- 提供了从逻辑卷到物理卷的映射(mapping from logical volumes to physical volumes)
- 平衡跨多个逻辑卷写入以及跨物理卷读取的负载
- 控制照片请求是走CDN 还是走 Cache (这个功能可以控制对 CDN 的依赖)。
- 标记逻辑卷为 read-only,为了便于操作,在机器的粒度进行标记。
如果 Haystack Directory 在 Haystack store 上丢失了数据,将删除相应的 mapping 条目,同时使用新的Haystack store 进行替换。
3. Haystack Cache #
Haystack Cache 接收 CDN 发来的请求,也可以通过 HTTP 直接和 cache 节点进行交互。Haystack cache 是一个分布式哈希表(一致性哈希?),使用照片 ID 作为 Key。
两种情况下 cache 节点会缓存照片
- 请求直接来自用户,而不是CDN(因此之前基于NFS设计的经验表明若 CDN cache miss,Haystack cache 也不太可能命中)
- cache miss,即从 store 获取了照片。
- 基于2,最近希望优化当上传照片后就写入缓存(局部性原理,刚写入 store 的数据很快会被读取)
4. Haystack Store #
store 管理多个物理卷(physical volume),每个卷包含数百万个文件。物理卷是一个非常大的文件(通常 100 GB),存储格式如:/hay/haystack_<logical volume id>.
通过逻辑卷 ID 和 offset 可以获取照片。元数据映射到内存中(mmap),访问元数据不需要磁盘操作(filename,offset,size)。
Physical volume layout #

图5显示了 haystack的布局。物理卷表示为一个大文件,由 superblock 和 其后的一系列 needle (指针)组成,每个 needle 对应一个存储在 haystack 里的照片(文件)。

表1解释了每个 needle 里面存储的字段的含义。
为了加速 needle 的访问,每个 haystack store 节点为每个卷维护一个内存数据结构,包括:
- <key, alternate key> 的 map
- needle 的 flag, size, offset
Photo Read #
cache 节点和 store 节点进行交互,它向 store 节点提供 <logical volume id, key, alternate key, cookie> 以请求照片。
- store 从内存中的数据结构查找相关元数据
- 如果照片没有被删除,store 找到对应的 volume,通过 offset 找到volume 中的 needle,并通过 size 读取整个 needle
- 最后验证 cookie和数据的完整性,通过后返回给 cache 节点。
Photo Write #
写入照片到 haystack 节点时,请求需要提供 <logical volumne id, key, alternate key, cookie, data> 。store 同步的 append needle image 到物理卷中,并更新内存中的数据结构(可能)。
append-only 的方式虽然简单,但是对于照片的更新操作比较麻烦。haystack 不允许覆盖 needle,haystack 是这样处理照片更新的:
- 如果新的 needle 写入与原始 needle 不同的逻辑卷,haystack directory 将更新应用程序的元数据,后续的请求将不再获取旧版本。
- 如果新的 needle 写入相同的逻辑卷,haystack store 节点将新 needle append 到相同物理卷。
- Haystack 根据 offset 来区分重复的 needle。即相同物理卷中 needle 的最新版本是 offset 最高的版本。
Photo Delete #
删除比较简单,在内存中的数据结构设置删除标志并同步到 volume 文件。请求照片首先会坚持该标志。needle 空间的回收通过 compact。
The Index File #
Haystack 通过索引文件(index file)而非扫描物理卷来重建内存中的映射。索引文件可以快速的定位卷中的照片。Haystack store 为的每个卷维护一个索引文件。索引文件是内存数据结构的 checkpoint。


图6显示了索引文件的布局,类似于物理卷文件的布局。需要注意的是,needle 与物理卷中的 needle 的顺序相同。
索引文件是异步更新的,这意味着索引可能引用旧的 checkpoint。
- 写入一张新照片时,store 节点同步地将 needle append 到卷文件的末尾,同时异步地将记录附加到索引文件。
- 当删除一张照片时,store 节点同步设置该照片needle 中的标志,但不更新索引文件。
但同时也带来了两个问题:
- needle 存在,但没有对应的索引记录。
- 索引记录不能反应 needle 是否被删除了。
Hasystack 把没有相应索引记录的 needle 称为孤儿 (orphan)。
-
重启时,store 节点按顺序检查每个孤儿文件,为其创建一个匹配的索引记录,并将该记录追加到索引文件中。store 节点会使用索引文件重建内存结构。
-
为了解决删除问题,haystack store 读取照片的 needle 后,检查 flag 查看是否删除,如果被标记为已删除,则更新内存中的结构,并通知 cache 节点没有找到该对象。
Filesystem #
Haystack 是一个对象存储,使用 Unix 标准的文件系统实现,但有些文件系统更适合Haystack,比如 XFS。
5. Recovery from failures #
像许多其他大型系统一样,在商品硬件上运行[5,4,9],Haystack还需要容忍各种故障:硬盘驱动器故障,行为不当的RAID控制器,不良主板等。
我们使用两种直接的技术来容忍故障——一种用于检测,另一种用于修复。
pitch-fork
- 定期检查每台的健康状况。pitch-fork 远程测试与每台haystack 的连接,检查每个卷的可用性,并尝试从 haystack store 节点读取数据。
- 如果pitch-fork 检查失败,那么将store 节点上的所有逻辑卷标记为只读。需要人工介入处理。
pitch-fork 检测的问题都可以快速修复。唯一比较复杂的情况是需要批量同步(bulk sync):使用其他副本卷文件来重置store 节点的数据。
主要问题要批量同步的数据量通常比每台节点上的网卡速度大几个数量级,导致平均恢复时间需要几个小时。我们正在积极探索解决这一限制的技术。
6. Optimizations #
Compaction #
compaction 是一种在线操作,可回收已删除和重复的 needles (重复是指具有相同 key 和alternate key 的 needle)所使用的空间。
- store 节点 通过将 needles 复制到一个新文件中来 compaction 文件,跳过任何重复或删除的条目。
- 在 compaction 过程中,两个文件都会被删除。
- 一旦 compaction 执行到文件末尾,将阻止对卷的任何修改,自动交换文件和内存中的结构。
Saving more memory #
store 节点在内存中维护了 flag, 当前仅使用该 flag 标记删除,一种优化的方式是将照片的 offset 设置为0,减少 flag 的内存消耗。
此外,store 节点不跟踪主存中的cookie值,而是在从磁盘读取一个 needle 后检查提供的cookie。
Batch upload #
多张照片合并在一起顺序写入磁盘。