这篇论文来自于阿里云盘古团队,主要解决了大规模分布式文件存储系统中的元数据遇到的的一些问题,包括令人头疼的分区后的数据局部性和负载均衡之间的天然矛盾,长路径解析延迟和令人头疼的 renmae 等问题。
摘要 #
现代数据中心更喜欢 allinone 的文件系统, 可以跨越整个数据中心并支持数10亿个文件. 这种系统会面临很多挑战, 包括
- 同时满足负载均衡和局部性
- 长路径解析
- near-root 热点
为了解决这些问题, 论文提出了 InfiniFS 文件系统, 通过以下方式尝试解决上述问题
- 将目录的元数据的访问数据和内容数据解耦
- 设计了可预测的并行路径解析
- 在客户端引入了乐观访问元数据缓存
通过评估, InfiniFS 可以在 1000 亿个文件下提供稳定的性能.
背景和动机 #
大规模可扩展的文件系统 #
分布式文件系统是数据中心的重要基础设施,但是元数据通常容易成为瓶颈,因此过去的数据中心内不得不将大的分布式文件系统拆分多个小的文件系统来达到扩展的目的。但是跨越整个数据中心的大规模文件系统更加理想,在先前的研究中,Facebook Tentonic 将多个小文件系统合并为一个大的文件系统。这样的系统具有以下方面的优势
- 更好的全局数据共享:多个文件系统,需要考虑数据移动以及上层计算服务面对多个文件系统时需要考虑分割等复杂的逻辑
- 提高资源利用率:多个文件系统中,一个集群空闲资源无法分配给某个热的集群
- 降低系统的复杂性:维护数千个文件系统集群在大型数据中心(如阿里云)中是费时且容易出错的
可扩展的元数据挑战 #
-
基于分区的元数据系统很难在高局部性和好的负载均衡之间达到平衡。
- 需要局部性的原因:规避分布式锁和分布式事务
- 需要负载均衡的原因:避免局部热点
- 先前系统的做法:基于分区、子树分区的方式可以达到很好的局部性,但牺牲了负载均衡。基于哈希分区的方式可能(需要经过精心设计)达到很好的负载均衡,但局部性会很差。
-
大规模分布式文件系统下,长路径解析很耗时
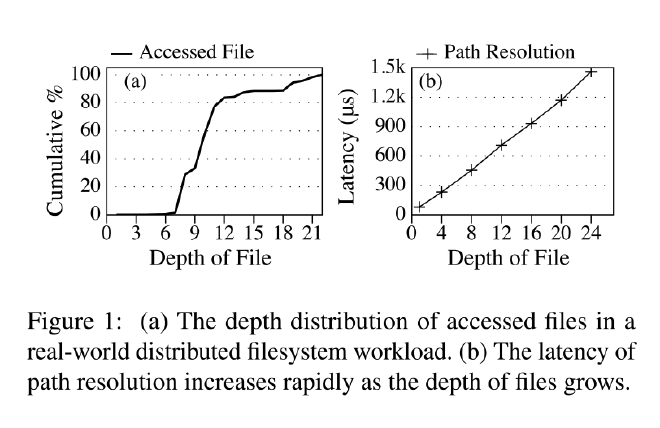
- 论文表示,在真实的系统过程中,大部分的路径解析长度超过 10(图1 a)
- 采用 Tentonic 的方式实现,对于长度 N 的路径,需要 N - 1 次网络请求,导致较高的延迟(图1 b)
-
客户端元数据缓存的一致性维护开销变得非常巨大,因为超大规模的文件系统通常需要服务于大量的并发客户端。
- 文件系统的吞吐量会收到根路径附近路径的限制,大部分客户端会选择缓存,但当前的缓存方式还是存在问题
- 根路径附近的路径在使用租约或者锁的方式下会导致该部分的元数据出现热点:客户端需要频繁的更新根路径附近的数据,会导致近根路径成为热点,大量客户端下的竞争会影响整体吞吐
了解真实的工作负载(阿里云) #

- 文件操作占所有操作的约 95.8%。
readdir是最常见的目录操作,占所有目录操作的约 93.3%。reaname和set_permission操作很少发生,仅占所有元数据操作的约 0.0083%。
设计和实现 #
INFINIFS 从过往的研究缺陷和自身的工作负载出发,提出了三个方面的改进
- 目录元数据解耦
- 使用可推测的目录 ID 进行路径解析
- 惰性缓存失效
INFINIFS 系统架构
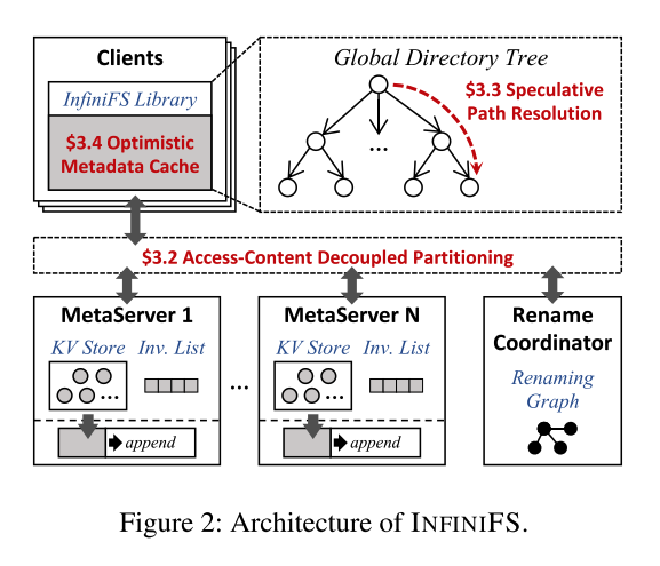
- Clients. 看到的是一个统一的、全局的文件系统元数据, 通过 fuse 交互。使用可推测的路径解析最小化延迟,使用乐观元数据缓存减少近根目录的负载。
- Metadata Servers. 通过目录元数据解耦的方式将元数据分区来同时满足局部性和负载均衡。每个 metadata server 使用运行在 NVMe SSD 上的 rocksdb 存储元数据。metadata server 使用 Inv List 延迟验证客户端的请求。
- Rename Coordinator. 单独处理 rename 和 set_permission 请求的服务,主要避免分布式事务,因为在阿里云的工作负载度量中,这两个操作的比例很少。
元数据解耦 #
InfiniFS 仔细研究了目录元数据, 认为过往的元数据哈希方式未能实现良好局部性的根本原因是将目录访问数据和内容数据当作同一份数据进行哈希. 因此 InfiniFS 提出了两者解耦分区的方式.
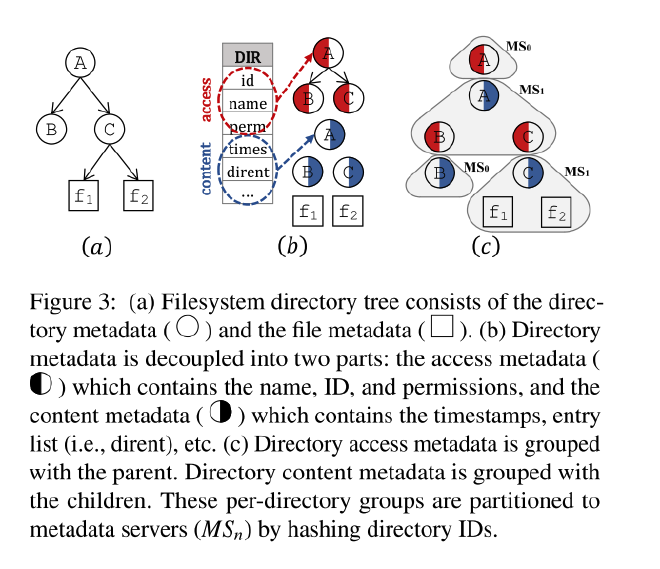
图3 (b) 展示了目录数据中, 哪部分属于访问数据(红色), 以及内容数据(蓝色).
InfiniFS 将文件操作分为三类
open/close/stat, 只读取单个分区文件元数据. 在 InFS 中, 只涉及到 内容元数据.create/delete/readdir, 涉及两个分区, 目标元数据分区和父节点分区. 在 InFS 中, 涉及父目录内容元数据和子目录访问元数据.rename, 通常跨多个分区
因此,INFINIFS 的核心是将content 和 access 分离,在分区时保证父目录内容数据和子目录或文件的访问数据在一个分区内,规避大部分操作所需的跨分区操作。
通过这种方式, 如图3(c) 所示, 基于哈希的分区可以很好的满足 open/close/stat/create/delete/ set_permission 的局部性要求. 先前的表1显示, 这些操作占所有元数据总操作的 90%, 内容元数据不聚集, 而是完全哈希, 所以大部分场景下也能很好的满足负载要求.
INFINIFS 使用 rocksdb 存储元数据, kv 格式如表 2 所示
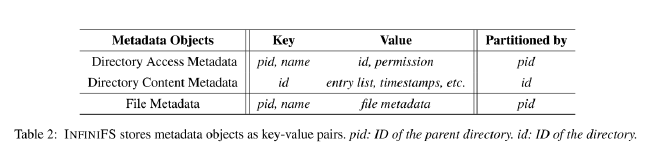
其中访问元数据分区 key 是 pid,内容元数据分区 key 是 id。
可预测的目录 ID #
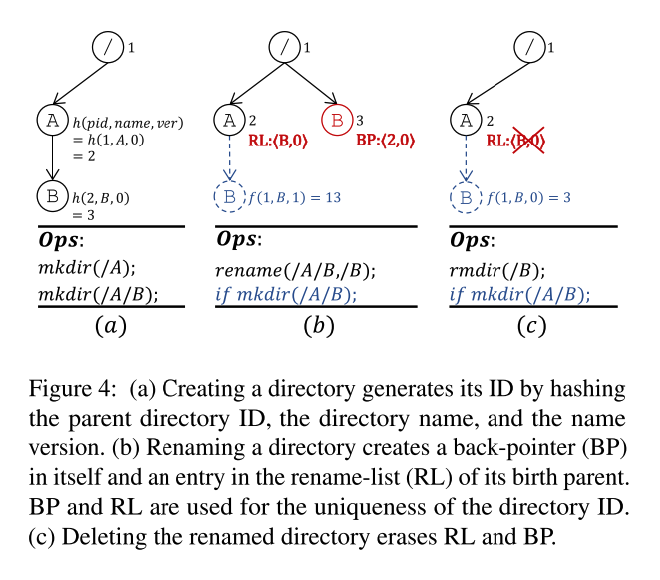
InfiniFS 路径解析推测依赖于可预测的目录 ID. 具体来说, InfiniFS 使用 <pid, name, version> 三元组来保证 ID 的唯一性, 使用 sha256 将三元组进行哈希生成目录 ID, sha 256 可以确保目录 ID 冲突概率非常低.
在 InfiniFS 中有三个操作涉及到目录 ID
creatingrenamedelete
Creating - 创建一个新的目录是,会对<parent_id, dir_name, name_version> 三元组 hash 来生成一个目录 id。图4(a) 中,mkdir(/A) 生成一个 id 为2,那么 mkdir(/A/B) 会基于父路径 A 的 id 2 生成新的 id。
Renaming - rename 时,仅 access 中的 id 需要更新,content 不需要更新。但是存在一个问题就是,例如图4 (b)中,先 rename(/A/B, B), 再 mkdir(/A/B), 会导致系统中存在两个 id 相同的目录,因此为了防止这种情况,增加了一个版本号来确保 id 的唯一性。
- rename 会在父目录创建一个 RL (record-list)记录一个版本用来区分相同名称的子目录, 格式为 <name, version>. 如图4(b) 中, A 首先在 RL 记录了 <B, 0>, 并且如果此时在 A 中新建一个子目录 B , 因为版本不同, 可以生成不同的目录 ID.
- 同时在 rename 的目录记录一个 BP (back-pointer) , 格式为 <birth pid, version> 来反向索引其原来重命名之前父目录的 RL 中的条目. 例如图4(b) 中,rename 的 B 记录了<2, 0>, 其中 2 是 A 的 id.
- 当目录 B 再次更新时,进需要更改 access 中的 id,其 content,BP 和原父亲目录 A 的 RL 保持不变。当 A 删除时,RL 保留,直到删除 B 时才会删除。
Deleting - 对于删除,如果删除带有 BP 的节点, 需要通过 BP 定位到 RL 并删除,当 RL 删除后,新建同名的子目录版本为 0, 如图4(c)所示。这里存在一个细节论文没有说明,当删除 B 时需要修改 A 的 RL,删除 B 的条目,由于 A 和 B 的 access 数据位于同一个节点,因此 RL 这部分的数据归为 access 数据,这样不需要跨节点。
ID uniqueness - 使用前面描述的三元组通过加密哈希(sha256)的方式生成唯一 ID ,冲突是很罕见的,如果发生冲突也很容易检查到,通过版本号、RL、BP 的方式处理 (有点类似于拉链法)。
并行路径解析 #
基于可预测的目录 ID ,InfiniFS 设计了并行路径查找来优化长路径解析的延迟,具体分为以下步骤
- 根路径 / 的目录 ID 为0,客户端从根路径开始计算所有中间路径的哈希值作为目录 ID 。
- 客户端并行发送所有查找中间路径的查找,每个对应的分区将检查对应的 ID、是否一致,如果目录 ID 不一致,则将当前目录 ID 返回给客户端。
- 重复步骤 1,2 直到解析完成。
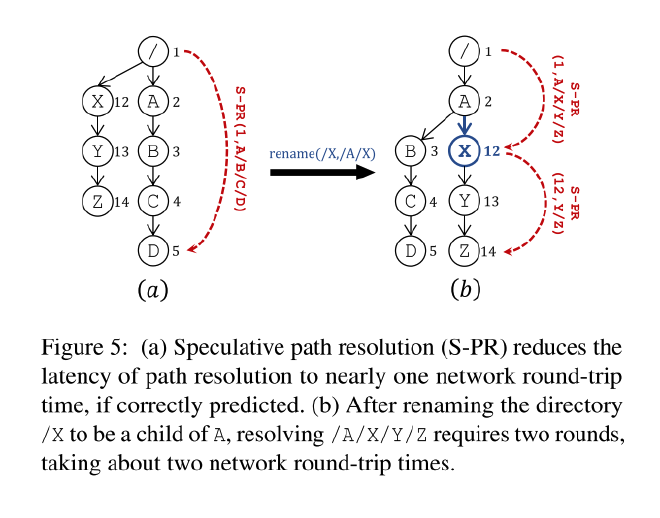
图5(a)展示了利用可预测的目录 ID 在所有中间路径都一致的情况下仅需要一个 RTT 就完成了。图5(b)展示了对于 rename 的处理,如果中间某个路径是 rename 过来的,那么目录 ID 将不一致,客户端需要重启查找。
乐观元数据缓存访问 #
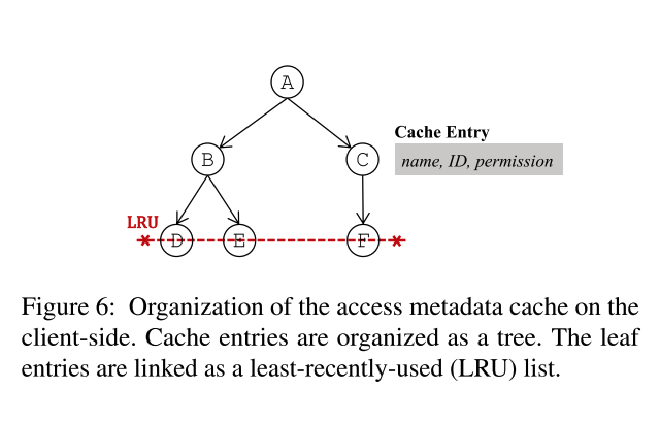
客户端缓存结构如图6所示
- 缓存条目为目录元信息,包括
<dir name, ID, permissions> - 缓存按照文件层次系统的树形结构存储
- 叶节点链接在一起组织成一个 LRU 链表
由于 rename, set_permission 等操作会导致缓存失效,失效时广播给客户端是不现实的,因此 InfiniFS 采用惰性失效(lazy invalidation)策略。以 rename 为例,当进行 rename 时,会将请求发送到一个中心的 rename 协调者服务,该服务处理 rename 后将请求广播给所有的元数据服务器(元数据服务器数量不会很多)。
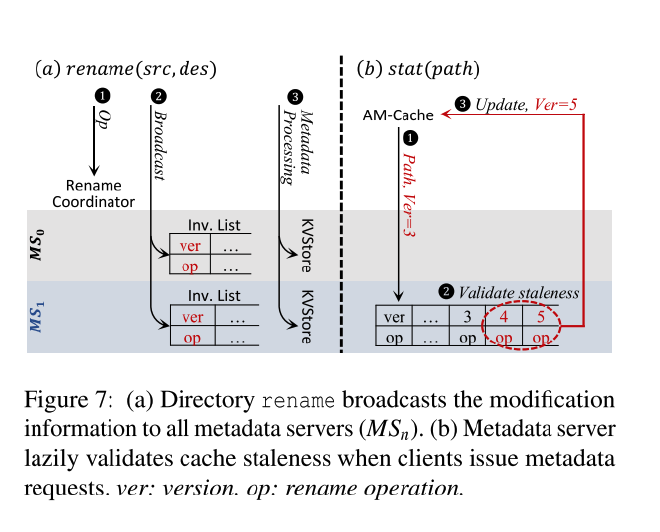
图7(a)显示了 rename 流程
- rename 操作发送到 rename 协调服务,rename 协调服务为每个 rename 操作分配一个增量的版本号。
- 锁定目录,广播 rename 操作到所有元数据服务器,所有的元数据服务器在本地维护一个无效列表 (Inv List),按照版本排序。
- 从源元数据服务器移动访问内容到目标服务器,并更新 RL 和 BP。
当 rename 执行后,客户端缓存将失效,图7(b)展示了如何处理的流程
- 客户端不知道是否过期,因此乐观的使用本地缓存。但是客户端在本地会维护版本号,表示缓存之前通过 rename 进行了更新。
- 当客户端拿着版本号访问元数据服务器时,元数据服务器通过检查在客户端版本和元数据服务器最新版本之间的 Inv List 来验证路径是否过期。
- 如果有效则返回成功,无效则终止请求并返回最新的 rename 信息,然后客户端更新缓存。
一致性 #
孤立循环 #
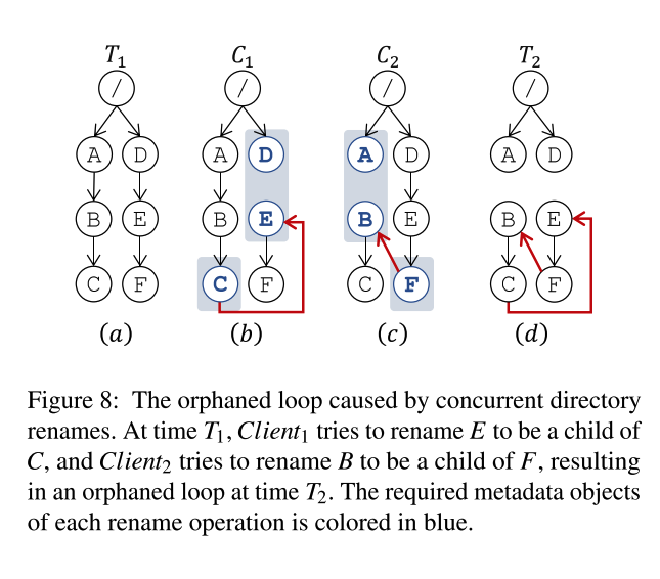
并发的客户端 rename 会导致孤立循环(orphaned loop)从而导致数据丢失,例如图8(d)中,如果需要访问 E, 但E rename 到 C 下,因此需要访问 A -> B -> C -> E, 又因为 C rename 到 F 下,此时需要访问从 D -> E -> F, 从而形成一个环路。
InfiniFS 通过维护一个 rename graph 跟踪当前正在进行的目录 rename,当进行 rename 时,通过运行图的环检测算法来检测是否会出现孤立循环,整个 rename 过程完成前,rename 的源目录和目标目录始终维护在图中。
前面也提到过,InfiniFS 使用一个中心化的 rename 服务,因为 rename 操作占比很低,中心化的服务可以满足。
元数据操作事务 #
对于单个节点
create/delete/open/close/stat/set_permission属于常见的操作,由于 INFINIFS 的元数据设计,这些操作在单个服务器上就可以满足。- INFINIFS 在单个服务器上使用带事务的 kv 数据库存储数据
- 当 INFINIFS 重启后询问 rename 服务初始化 Inv List。
对于多个节点
mkdir/rmdir/statdir/rename涉及多个元数据服务器- INFINIFS 使用两阶段提交协议,参与事务的元数据服务器选择一个作为协调者,每个元数据服务器使用 wal 持久化事务状态
对于rename
- 前面提到过,rename 过程会涉及操作多个元数据服务器,这也是通过分布式事务来实现的,不同之处在于选择 rename 作为协调者。
- 如果协调器在广播提交时崩溃,重启后会重新广播来恢复事务。
实验结果 #
元数据性能整体度量 #
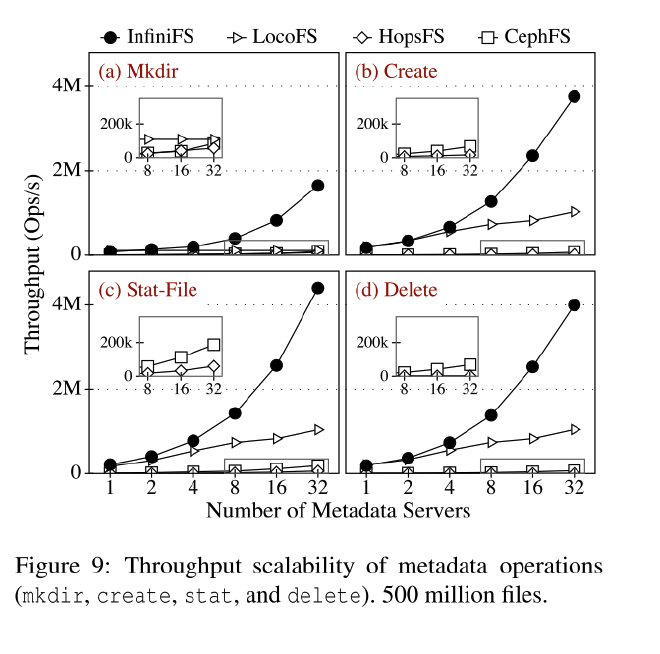
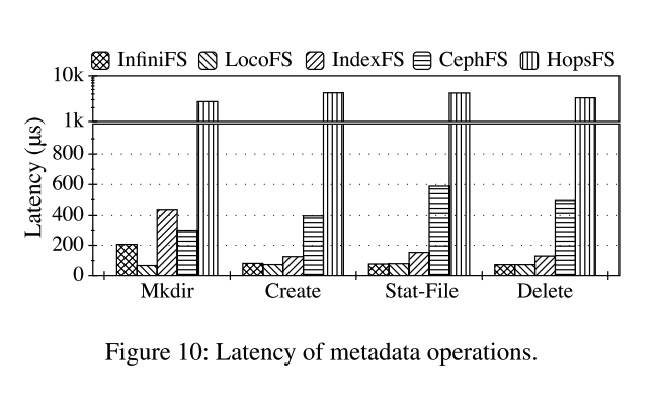
使用mdtest生成一个四阶段工作负载,分别测量目录 mkdir、文件创建、文件统计和文件删除操作的性能
吞吐
延迟
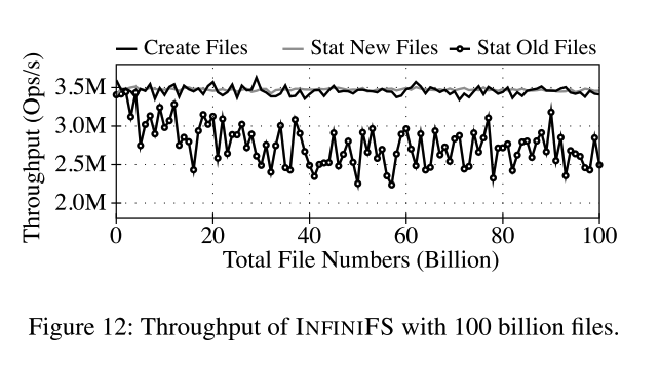
大规模目录树 #
缓存效率 #

Rename #
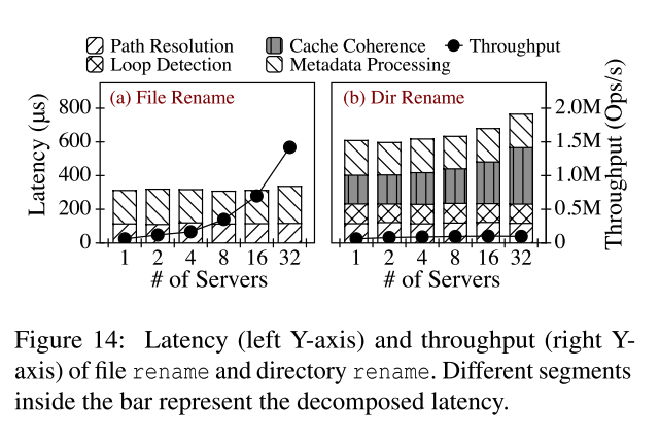
重解析的开销 #
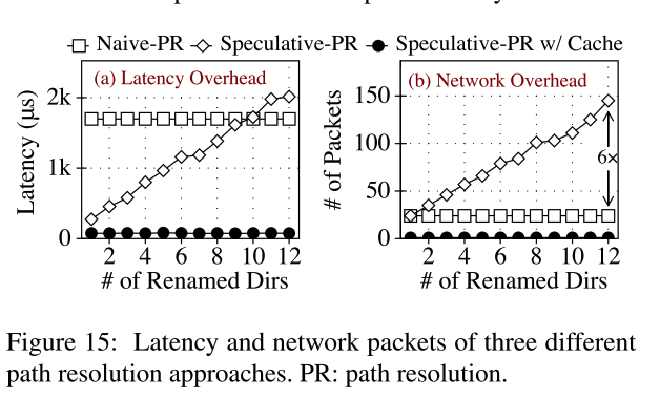
总结 #
讨论和分析 #
没有说元数据分区内的数据如何保障, 一致性哈希, 一致性?
delete RL 和 BP 可能不在同一个分区,如何处理?如果不是同步的,那么 BP 删除了,RL 还没即使删除,新建了一个同名的子目录 B,此时假设版本 为 1,B 新建完成之后, RL 被删除了,此时 B 应该恢复版本为 0 吗?这个如何处理?
单个协调者,主要是认为 rename 操作很少,单个协调者足够满足了。
谁来协调执行 rename 的步骤
如果 rename 出现环,没说怎么处理