概述 #
这篇论文发布于 USENIX 17’s,主要对 FUSE 进行了系统的分析和评估。在过去,用户空间文件系统通常认为不够成熟,大部分认为这类系统还处于玩具阶段,但也有一些系统在用户空间文件系统中开发出生产级别的文件系统。为了搞清楚用户空间的文件系统是否可以在生产级别使用,以及和内核文件系统性能差距到底多大,该论文使用 FUSE 这个被广泛使用的系统进行了评估。虽然 FUSE 被广泛使用,但对于 FUSE 的实现细节的研究却很少,论文首先对 FUSE 的原理进行了深入的分析,不幸的是,由于 FUSE 缺少一些更细粒度的统计信息,因此论文又增加了许多有用的统计信息和 Trace 信息来提供更细粒度的数据。最后实验表明,根据所使用的工作负载和硬件,由FUSE引起的性能下降可以是完全察觉不到的,另一方面,一些工作负载即使优化也会导致高达 -83% 的性能下降;相对CPU利用率可提高31%
背景 #
用户空间文件系统近十年越来越流行的四个原因
- 现有的文件系统基于 FUSE 堆叠了专门的功能(例如,重复数据删除和压缩)
- 可以快速产出文件系统原型
- 有几个现有的内核级文件系统被移植到用户空间(例如,ZFS [45],NTFS [25])。
- 更多的项目依赖用户文件系统来实现:IBM的 GPFS 和 LTFS,Nimble Storage 的 CASL,HDFS,GFS,GlusterFS,DDFS
使用用户态的文件系统的讨论
- 用户态的文件系统性能开销有多大?
- 在用户态开发文件系统能简单多少?
该论文选用 FUSE 作为评估对象,理由是
- FUSE 体系结构有些复杂
- FUSE 内部细节相关资料很少
- FUSE的源代码可能很难分析:异步、用户态内核态通信
- FUSE 越来越普及,对其实现的详细分析对许多人来说变得很有价值
该论文评估 FUSE 的方式
- 基于 FUSE 和 ext4 实现了一个 StackFS 作为评估 FUSE 时所需的文件系统
- 为 FUSE 设计和构建了丰富的统计信息,通过这个工具提取出更详细的信息
- 基于统计信息识别 FUSE 的瓶颈,并解释说明不同的工作负载之间为什么导致如此大的性能差异
FUSE 设计 #
架构 #
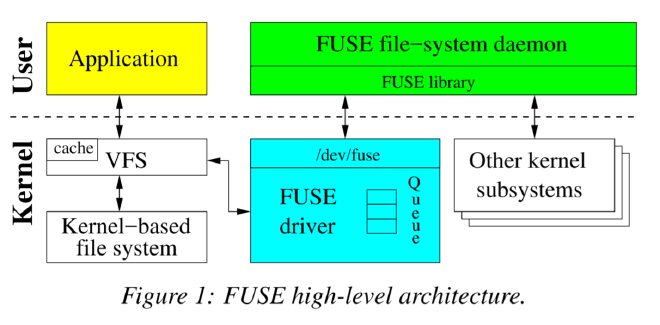
内核部分是作为Linux内核 module 实现的,当加载时,向Linux的 VFS 注册一个fuse文件系统驱动程序,该程序充当用户态程序和内核交互的文件系统代理。
驱动程序分配 FUSE request 并将其放入FUSE队列中,此时,提交请求的的进程通常会被置于等待状态。 然后,FUSE的用户态进程通过读取 /dev/fuse 从内核队列中挑选请求并处理。
需要注意的时,处理请求可能需要重新进入内核:例如在在 ext4 之上堆叠实现 FUSE文件系统的情况下,用户态进程还会再次将请求交给底层文件系统(ext4)。
当处理完请求后,FUSE 守护进程将响应写回 /dev/fuse,然后,FUSE的内核驱动程序将请求标记为已完成,并唤醒发送请求的用户进程。
应用程序的某些文件系统操作可以在不同 FUSE 用户态进程交互的情况下完成。例如,如果读取的页面在内核中缓存,可以从内核页面缓存中的文件中读取数据,不需要转发到FUSE驱动程序。
实现细节 #
用户态和内核态的接口 #
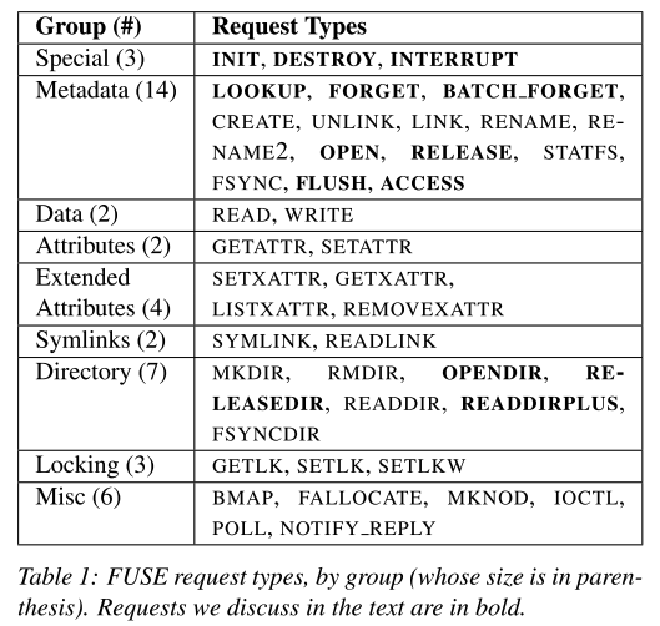
当内核需要于用户态程序通信时,会创建一个 request 结构,表1按照语义分组列出了 43 种 FUSE 所有的请求类型,可以看到大多数请求都是直接和 VFS 映射的。接下来重点关注的是表1种加粗的请求,这些请求不是很直观。
INIT , DESTORY, INTERRUPT :当文件系统被挂载时,内核会产生 INIT 请求。然后,用户空间和内核协商
- 操作的协议版本
- 相互之间支持的能力集合(例如,可以支持 READDIRPLUS 或 FLOCK)
- 各种参数设置(例如,FUSE 预读大小)
当文件系统卸载时,内核会产生 DESTROY 请求,此时用户态的守护进程应该执行所有必要的清理。一旦发送 DESTROY 请求后,后续内核不会继续发送请求,并且从 /dev/fuse 读取将返回0。
当内核先前发送的请求无效时(例如读取文件的用户程序终止),内核会发送 INTERRUPT 请求,该请求包含一个 #sequence 序号,该序号由内核分配,也用于定位已经完成的请求。
每个请求包含一个 uint64_t node ID 用于标识内核和用户态中的 inode。LOOKUP 请求执行 path 到 inode 的转换。每次查找或者新建 inode 时,内核都会将 inode 缓存,当从 dcache 删除 inode 时,内核会发送一个 FORGET 请求到用户态进程,此时用户态的进程可以释放相应的护具结构。BATCH_FORGET 则允许内核在一个请求中驱逐多个 inode。
用户应用程序打开一个文件时内核会发送一个 OPEN 请求到用户态的守护进程,后者可以选择性的为打开的文件分配一个 64-bit file handle 结构。每当打开的文件关闭时会发送 FLUSH 请求,当打开的文件引用数量为 0 时会发送 RELEASE 请求。
OPENDIR 和 RELEASEDIR 请求针对于目录,类似于 OPEN 和 RELEASE。READDIRPLUS 请求类似于 READDIR 但仅包含每个 entry 的元数据,这个请求可以让内核预填充 inode 缓存。
当内核查看应用进程访问文件的权限时,会发送一个 ACCESS 请求,FUSE 守护进程可以实现自定义的权限逻辑。需要注意的是,用户使用默认权限 mount FUSE 时,内核可以根据这个基于标准的 unix 属性(ownership,permissions)进行授权,这种情况下内核不会发生 ACCESS 请求。
库和API #
FUSE API 分为 low-level API 和 high-level API 两类,侧重点也不同。低级别 API 需要和内核通信,高级别 API 构建在低级别 API 之上,允许跳过 path-to-inode 实现,因此高级别 API 不会显式的操作 inode,操作的对象路径文件路径。此外,高级别 API 还提供了像 chwon(), chmod() 和 truncate() 等api。文件系统开发者需要再易用性和底层弹性上做取舍来考虑使用哪种 api。
队列 #
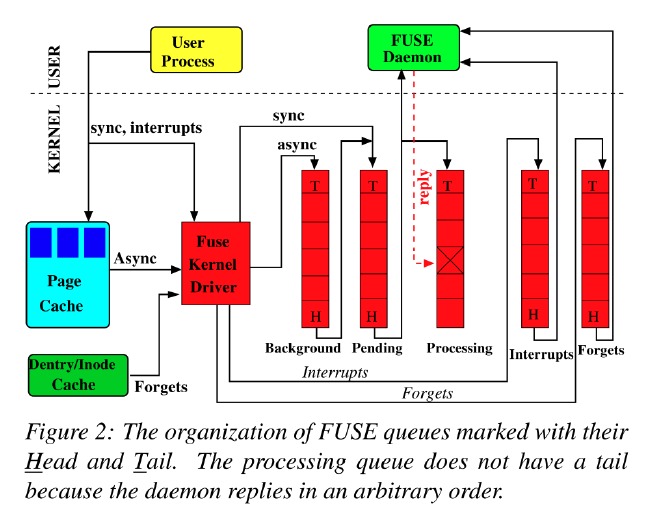
如图 2 所示,FUSE 内部维护了5个队列
- interrupts
- forgets
- pending
- processing
- background
用户态守护进程读取 /dev/fuse 获取请求,通过写入 /dev/fuse 回复请求。
-
interrupts 队列中的请求被优先处理
-
对于 forgets 和非 forgets (pending 等)的请求选择方式为:对于每选择 8 个非 forgets 的请求,就会选择 16 个 forgets 请求。这减少了 forgets 请求突发饿死其他请求。
-
pending 队列中的请求按照先进先出传送到用户态守护进程,同时移动到 processing 队列。因此当 processing 队列为空是,用户态的守护进程读取 /dev/fuse 会阻塞。当用户态的守护进程回复一个请求时,相应的请求从 processing 队列中删除。
-
background 队列用来保存异步请求。通常情况下之后读请求会进入 background 队列,写请求只有在 writeback cache 开启时。如果开启,应用进程的写入首先会在 page cache 中积累,稍后由 bdflush 线程唤醒刷新。在刷新时,fuse 就会创建异步请求并放入到 background 队列,background 的队列的请求逐步进入到 pending 队列进行处理。因此,FUSE 将驻留在 pending 队列的最大值限制为 12,这样做的目的是 fuse 最大的处理线程为 12,如果不限制会对同步请求造成延迟。
队列的长度没有显示的设置方式,当 pending 队列和 processing 队列中的异步请求数达到可调拥塞阈值参数的值(最大后台的75%,默认为9)时,FUSE通知Linux VFS它拥塞;然后,VFS限制向该文件系统写入的用户进程。
Splicing 和 FUSE buffers #
对 /dev/fuse 调用 read() 和 write() 会导致内核和用户空间之间的数据拷贝,通常这两个调用会携带大量的数据,为了减少拷贝的开销,FUSE 使用了 Linux 内核提供的 splicing 技术来避免数据拷贝。
splicing 是 Linux 内核加入的一种 zero-copy 方法,原理是通过 pipe buffer 创建一组内核内存页面的引用技术指针,数据拷贝过程拷贝的是指针。
如果用户空间守护进程实现了 write_buf(), FUSE 会 splicing 来自 /dev/fuse 的数据。
多线程 #
FUSE 使用多线程来支持并发性。在多线程模式下,FUSE 守护进程会先启动一个线程,如果有两个以上的请求,FUSE 会启动一个额外的线程,每个线程处理一个请求,每个线程在处理请求结束后会检查当前是否超过 10 个线程,如果是,则线程会退出。FUSE 库没有提供显示的参数控制线程数量。隐式限制主要有两个原因
- 默认情况下(max_background 参数)最多有12个异步请求在挂起队列中
- 对于每个 INTERRUPT 和 FORGET 请求, 都会调用一个新线程,如果这两个请求很少的情况下,FUSE 守护进程最多会存在 12 个 线程。
回写和最大写大小 #
FUSE 默认按照 4KB 页大小同步写入,对于写入一个大文件的工作负载可能会产生性能问题。为了解决这个问题,FUSE 通过页面缓存的回写策略异步写入,通过更改 max_write 大小来调整(最大限制为 32 个页面)。
评估手段 #
Stackfs #
论文设计了 Stackfs 来更加准确的评估 FUSE、Stackfs 将 FUSE 的请求直接转发到底层的文件系统。stackfs 使用 low-level api,因为大多数复杂的生产系统通常使用 low-level 的 api 来保持灵活性并避免 high-level api 的开销。
Inode Stackfs 将每个文件表示为一个 inode。inode 仅存储在内存中,当 mount 文件系统时初始化。inode 保存了底层文件的路径、inode、引用计数。
Lookup 执行 lookup 时,stackfs 使用 stat(2) 检查底层的文件系统,如果存在,则分配一个 inode,inode 使用 stat 得到的内存地址进行类型强转表示。stackfs 将 inode 存储在 hash 表中,当执行 lookup 时,引用计数 +1,当收到 FORGET 请求时,引用计数 -1,当计数为 0 时释放 inode。
文件创建和打开 当文件创建时,stackfs 在底层文件系统创建成功后往 hash 表添加一个 inode,当打开文件时,stackfs 将底层文件的文件描述符保存在 file handle 中。
性能统计和追踪 #
FUSE 现有的手段不能很好的对 FUSE 性能进行深入分析,为了度量 FUSE 内核和用户态各个阶段的开销,论文为 FUSE 增加了更多的性能指标。具体来说,添加了一个二维数组,行(0-42)表示请求的类型,列(0-31)表示时间。添加了4个数组,前3个数组在内核中,用于捕获 background, pending, processing 队列的花费时长。对于 processing 队列,这个捕获的时间也包括发送到用户态的时间。第4个数组在用户空间追踪守护进程处理请求花费的时间。4个数组总的内存开销为 48KiB,且只需要很少的指令就可以完成更新。
fuse 提供了一个 fusectl 来控制 fuse 行为。该命令通常挂载在 /sys/fuse/connections/,每个挂载的 fuse 实例也会创建一个目录,每个目录包含控制文件,可以终止连接、检查正在处理的请求总数、调整后台请求数量和阈值。论文在这些目录中添加了3个新的文件用于从内核中导出统计信息,对于用户态,守护进程添加了 SIGUSR1 信号处理程序,触发时打印到后台指定的日志文件中。
为了更详细的了解 fuse 的行为,需要使用 tracing。当守护进程在 debug 模式下运行时,fuse 库提供了 tracing,但是对于内核则没有。论文使用 linux 的静态跟踪点机制在内核添加了30多个跟踪点,主要为了在复杂的写回逻辑、读取和一些元数据操作期间监控请求的形成。 tracing 帮助了解了队列在实验过程中增长的速度,单个请求中放入了多少数据以及原因。
评估方法 #
FUSE 配置调整
Stackfs 采用了 StackBase(基本配置) 和 StackOpt(优化配置) 两种配置。相比于 StackBase,StackOpt 调整了
- 开启
writeback缓存 max_write大小从 4KiB 增加到 128Kib- 用户态守护进程开启多线程模式
- 开启
splice_read,splice_write,splice_move
工作负载
- rnd 表示随机,seq 表示顺序
- rd 表示读取,wr 表示写入,cr 表示创建,del 表示删除
- Nth 表示 N 个线程,Mf 表示 M 个文件
环境设置
- HDD(Seagate Savvio 15K.2,15 KRPM,146 GB)和 SSD(Intel X25-M固态硬盘,200 GB)
- Dell PowerEdgeR710 machines with 4-core Intel Xeon E5530 2.40GHz,4GB
- Centos7 + Ext4 文件系统