7.访问模式 #
7.1 定义顺序和随机I/O操作 #
在接下来的部分,我打算从“顺序”或“随机”入手。如果I/O操作开始的逻辑块地址(LBA)直接跟着前一个I/O操作的最后LBA,则称为顺序访问。如果不是这样,那这个I/O操作称为随机访问。这很一点重要,因为FTL执行动态映射,相邻的逻辑空间地址可能被应用于不相邻的物理空间地址上。
7.2 写入 #
基准测试和生产商提供的数据表显示出,随机写入比序列写入要慢,但这并不总是对的,因为随机写入的速度实际上取决于工作负载的类型。如果写入比较小,小是说小于簇(译注:关于簇的翻译请见上一篇文章)大小(就是说 <32MB),那么是的,随机写入比顺序写入慢。然而,如果随机写入是按照簇大小对齐的,其性能将会和顺序写入一样。
解释如下。如第六节所说,SSD的内部并行机制通过并行和交错,允许簇中的块同时访问。因此,无论是随机或者序列写入,都会同样将数据写入到多个通道和芯片上,从而执行簇大小的写入可以确保全部的内部并行都用上了。簇上的写入操作将在后边的7.3节解释。至于性能,如来自 [2]和 [8] 的图8和图9所示。当基准测试写入缓存和簇大小(大部分SSD是16或32MB)相同或者更大时,随机写入达到和顺序写入同样高的吞吐量。
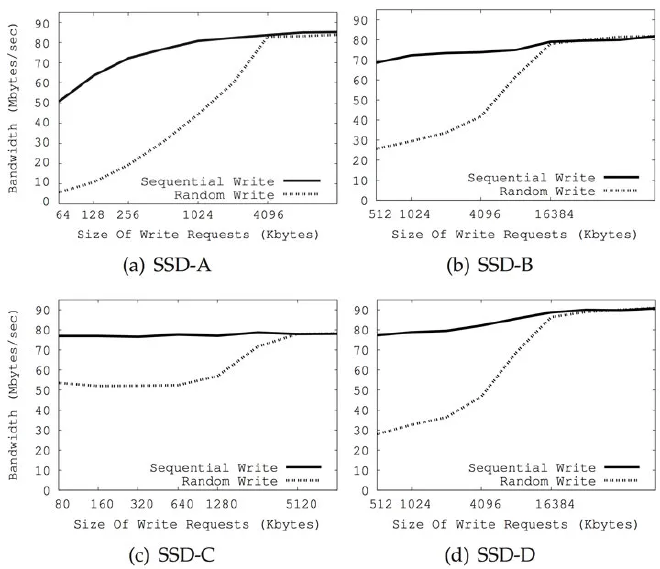
图8:4块SSD顺序写入负载和随机写入负载效率对照——根据Kim et al., 2012 [2] 重制

图9:3块SSD顺序写入负载和随机写入负载效率对照——根据Min et al., 2012 [8]重制
然而,如果是小写入——小是指比NAND闪存页小,就是说**<16 KB——主控需要做更多的工作以维护用来做块映射的元数据上**。确实,一些SSD使用树形的数据结构来实现逻辑块地址和物理块地址之间的映射 [1],而大量小随机写入将转换成RAM中映射的大量更新。因为这个映射表需要在闪存中维护 [1, 5],这将导致闪存上的大量写入。而顺序工作负载只会导致少量元数据的更新,因此闪存的写入较少。
另外一个原因是,如果随机写入很小,其将在块中引起大量的复制-擦除-写入操作。另一方面,大于等于块大小的顺序写入可以使用更快的交换合并优化操作。再者,小随机写入显然会有随机的无效数据。大量的块将只有一页是无效的,而非只有几个块全部无效,这样会导致作废的页将遍布物理空间而非集中在一起。这种现象被称为内部碎片,并导致清除效率下降,垃圾回收进程通过请求大量的擦除操作才能创建空页。
最后关于并发性,已有的研究已经显示出,单线程写入大数据和用很多并非线程写入大量小数据是一样快的。确实,大写入可以确保SSD所有的内部并行都用上了。因此试着实现并发的多个写入并不会提高吞吐量 [1, 5]。然而,多并行写入和单线程访问相比将会有延迟 [3, 26, 27]。
7.3 读取 #
读取比写入要快。无论是顺序读取还是随机读取,都是这样。FTL是逻辑块到物理块地址的动态映射,并且将写入分布到各个通道上。这个方法有时候被称为“基于写入顺序的”映射 [3]。如果数据是以和原本写入的顺序完全不相关,完全随机读取的,那就无法保证连续的读取分布在不同的通道。甚至有可能连续的随机读取访问的是同一个通道中的不同块,因此无法从内部并行中获取任何优势。Acunu写了一篇博文讲了这个情况,至少在他们测试的硬盘上是这样,读取性能和读取访问模式与数据原始写入方式有多相似直接挂钩 [47]。
下面的图10表示出一个有两个通道4块芯片,每块芯片只有一个面的SSD。注意这技术上是不成立的,因为SSD每块芯片都有两个以上的面,但为了保持图片简洁,我决定只让每块芯片只有一面。大写字母代表大小和NAND闪存块相同的数据。图10上边的操作是顺序写入4个块:[A B C D],在这个例子里刚好是一个簇的大小。写操作通过并行和交错被分配到四个面上使其更快。即便4个块在逻辑块地址上是连续的,但他们存储在四个不同的面中。
基于写入顺序的FTL,面上所有的块被选作写入操作的可能是近乎于相同的,因此簇不必由各自面上相同物理块地址(PBN)的块组成。在图10的例子中,第一个簇由四个不同面上的块组成,各自面上的PBN分别是1, 23, 11, 和51。
图10下边有两个读取操作,[A B E F] 和 [A B G H]。对于[A B E F]来说,A和E在同一个面上,这使其必须只从一个通道的两个面上读取。对于[A B G H]来说,A、B、G、和H存储在四个不同的面上,因此**[A B G H]能够同时从两个通道的四个面上读取**。从更多的面和通道上读取可以从内部并行上获得更多的优势,从而有更好的读取性能。

图10: 利用SSD的内部并行
内部并行的一个直接结果是,使用多线程同时读取数据不是提升性能所必须的。实际上,如果这些并不知道内部映射的线程访问这些地址,将无法利用内部并行的优势,其可能导致访问相同的通道。同时,并发读取线程可能影响SSD预读能力(预读缓存) [3]。
SSD生产商通常不说页、块和簇的大小。但可以通过运行简单的工作负载来进行反向工程获取大部分SSD的基础特征 [2, 3]。这些信息可以用在优化读写操作的缓存大小上,同时可以在格式化硬盘的时候使得分区与SSD内部特征对齐,如8.4节中所说。
7.4 并发读写 #
小的读和写交错会导致性能下降 [1, 3]。其主要原因是对于同一个内部资源来说读写是相互竞争的,而这种混合阻止了诸如预读取机制的完全利用。
8.系统优化 #
8.1分区对齐 #
如3.1节中解释的那样,写入是页对齐的。大小是页大小,并且和页大小是对齐的写入请求,会被直接写入到一个NAND闪存物理页中。大小是页大小,但不对齐的写入请求将会被写入到两个个NAND闪存物理页中,并导致两个读-改-写操作 [53]。因此,确保用来写入的SSD分区是和硬盘采用的物理NAND闪存页的大小对齐是很重要的。很多教程和指引都讲了格式化的时候如何将分区对齐SSD的参数 [54, 55]。稍微Google一下就能知道某型号的SSD的NAND闪存页、闪存块和簇的大小。就算是没法拿到这些信息,通过一些反向工程也可以揭示出这些参数 [2, 3]。
有人指出分区对齐可以显著地提高性能 [43]。还有人指出,在对某块硬盘的测试中,绕过文件系统对硬盘直接进行写入会提高性能,不过提高很小 [44]。
8.2 文件系统参数 #
如5.1节所说,并不是所有的文件系统都支持TRIM命令 [16]。Linux 2.6.33及以上,ext4和XFS支持TRIM,但仍需要使用discard参数来启用。此外,还有一些其它的微调,如果没有什么东西需要的话,可以通过移除relatime参数并添加noatime, nodiratime [40, 55, 56, 57] 将元数据的更新关掉。
8.3 操作系统I/O调度器 #
Linux上的默认I/O调度器是CFQ调度器(Completely Fair Queuing 完全公平队列)。CFQ被设计用来通过将物理上接近的I/O请求组合到一起从而最小化机械硬盘寻道时间的。这种请求重新排序对于SSD是 不必要的,因为它们没有机械部分。几个指引和讨论文章主张将I/O调度器从CFQ换为NOOP或Deadline将会减少SSD的延迟 [56, 58]。然而子Linux 3.1版之后,CFQ为固态硬盘提供了一些优化 [59]。基准测试同样显示出调度器的性能取决于应用在SSD上的工作负载(即应用),和硬盘自身 [40, 60, 61, 62]。
我个人从中学到的是,除非工作负载十分特殊并且特定应用的基准测试显示出某个调度器确实比另一个好,CFQ是一个比较安全的选择。
8.4 交换分区 #
因为相当数量的I/O请求是由向硬盘上进行页交换导致的,SSD上的交换分区会增加损耗并显著降低寿命。在Linux内核,vm.swappiness参数控制想硬盘交换页的频率。其可用值是0到100,0表示内核需要尽可能的避免交换。以Ubuntu来说,默认swappiness是60。当使用SSD的时候,尽可能降低这个值(就是说设为0)会避免不必要的向硬盘的写入并增加其寿命 [56, 63]。一些教程建议设置为1,而在实践中实际上和0一样的 [57, 58]。 另外的做法的使用内存作为交换分区,或者完全避免使用交换分区。
8.5 临时文件 #
所有临时文件和日志文件没有必要,否则只是浪费SSD的生命周期。一些可以保存在RAM中的文件可以使用tmpfs文件系统 [56, 57, 58]。