概述 #
LSMT 基本结构要求保持一个内存索引,配合 wal 实现高性能的写入,memtable 则是 leveldb 实现的内存数据结构。
- 所有写入会追加到 memtable 中,memtable 只会新增数据,不会删除数据
- 插入、更新操作添加是一个新的记录到 memtable,而删除操作添加一个删除标记
LSMP 没有要求内存索引具体的数据结构,可以使用多种数据结构实现,主要考虑能够高效支持点查和范围扫描,例如
- 红黑树
- 跳表
- BTreeMap
leveldb 使用 SkipList 作为内存索引
Arena #
memtable 内存分配是个关键,如果每次 insert 数据时需要分配内存,对于比较小的 key/value 来说内存分配调用的开销比较昂贵。leveldb 使用 arena 优化这个问题。基本思想为:每次分配一个的一个内存区域,需要分配内存时,首先从这个内存区域里分配,如果不满足则继续增长 arena。
内存分配需要关注内存碎片问题,然而 leveldb 从来不会从 memtable 中删除数据,因此 arena 实际上是一个连续增长的区域,实现起来比较容易,但又特别适合 leveldb 这种场景。
具体来说,arena 结构上是一个连续的多个 block 的内存区域,但 block 的大小不是定长的,默认情况下每个 block 大小为 4KB,但是
- 对于小于 1KB 的块,共用 4KB 大小 block
- 对于大于 1KB 的块,按照实际的大小分配 block,避免在 4KB 大小的 block 中浪费空间
+-------------------+-------------------+-------------------+-------------------+
| | | | |
| char* (4kb) | char* (>1kb) | char* (>1kb) | char* (4kb) |
| | | | |
+-------------------+-------------------+-------------------+-------------------+
| | | |
| | | |
| | | |
v v v v
+------------+ +------------+ +------------+ +------------+
| 128 byte | | | | | | |
+------------+ | | | | | |
| | | | | | | 456 byte |
| 256 byte | | | | | | |
| | | | | 1049 byte | | |
+------------+ | | | | +------------<---+--------- alloc_ptr_
| | | | | | | | |
| | | 2048 byte | | | | | |
| 512 byte | | | | | | | |
| | | | +------------+ | | |
| | | | | | |
| | | | | | |
+------------+ | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | +------------+ | | |
| | | | |
| | | | +----- alloc_bytes_reamming_
| | | unused | |
| | | | |
| | | | |
| | | | |
| unused | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
+------------+ +------------<---+
alloc_ptr_ 指向最后一个 block 可用内存开始位置,alloc_bytes_reamming_ 表示该 block 剩余内存大小。
// vim util/arena.h +16
class Arena {
// Allocation state
char* alloc_ptr_;
size_t alloc_bytes_remaining_;
// Array of new[] allocated memory blocks
std::vector<char*> blocks_;
// Total memory usage of the arena.
//
// TODO(costan): This member is accessed via atomics, but the others are
// accessed without any locking. Is this OK?
std::atomic<size_t> memory_usage_;
};
内存按照 8 字节对齐分配,不满足使用 slop 填充
// vim util/arena.cc +38
char* Arena::AllocateAligned(size_t bytes) {
const int align = (sizeof(void*) > 8) ? sizeof(void*) : 8;
static_assert((align & (align - 1)) == 0,
"Pointer size should be a power of 2");
size_t current_mod = reinterpret_cast<uintptr_t>(alloc_ptr_) & (align - 1);
size_t slop = (current_mod == 0 ? 0 : align - current_mod);
size_t needed = bytes + slop;
char* result;
if (needed <= alloc_bytes_remaining_) {
result = alloc_ptr_ + slop;
alloc_ptr_ += needed;
alloc_bytes_remaining_ -= needed;
} else {
// AllocateFallback always returned aligned memory
result = AllocateFallback(bytes);
}
assert((reinterpret_cast<uintptr_t>(result) & (align - 1)) == 0);
return result;
}
fallback 处理大于 1kb 的 block
// vim util/arena.cc +20
char* Arena::AllocateFallback(size_t bytes) {
if (bytes > kBlockSize / 4) {
// Object is more than a quarter of our block size. Allocate it separately
// to avoid wasting too much space in leftover bytes.
char* result = AllocateNewBlock(bytes);
return result;
}
// We waste the remaining space in the current block.
alloc_ptr_ = AllocateNewBlock(kBlockSize);
alloc_bytes_remaining_ = kBlockSize;
char* result = alloc_ptr_;
alloc_ptr_ += bytes;
alloc_bytes_remaining_ -= bytes;
return result;
}
AllocateNewBlock 根据 bytes 大小分配 block
// vim util/arena.cc +58
char* Arena::AllocateNewBlock(size_t block_bytes) {
char* result = new char[block_bytes];
blocks_.push_back(result);
memory_usage_.fetch_add(block_bytes + sizeof(char*),
std::memory_order_relaxed);
return result;
}
析构函数释放分配的所有内存块
// vim util/arena.cc +14
Arena::~Arena() {
for (size_t i = 0; i < blocks_.size(); i++) {
delete[] blocks_[i];
}
}
SkipList #
查找 #
查找是算法的核心,因为插入和删除依赖查找
查找伪代码

- 从跳表最上层的链表头部开始
- 在该链表水平方向上查找,直到当前元素大于或等于目标
- 如果当前元素等于目标,则查找结束
- 如果当前元素大于目标,返回到前一个元素,并通过该元素跳到下一个列表
- 重复这个过程,直到跳到最底层的链表
- 如果没有找到,则返回当前节点
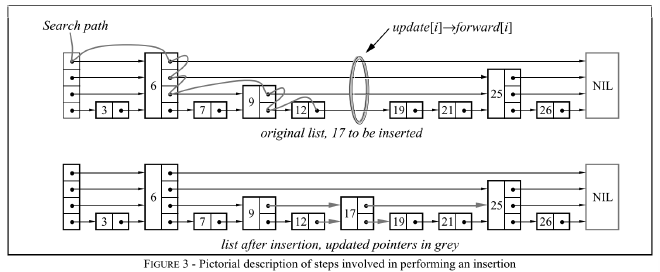
例如查找图3中的 17
- 首先最顶层的链表中查找到最后一个节点也没有大于等于 17 的节点,因此通过最后一个节点的前一个节点 6 跳到下一层
- 下一层中节点
25 > 17,因此还是通过前一个节点6跳到下一层 - 下一层中仍然是节点
25 > 17,因此通过前一个节点9跳到下一层 - 下一层中仍然是节点
25 > 17,因此还是通过前一个节点9跳到下一层 - 下一层中节点
19 > 17,但由于是最底层,说明没有找到,返回19这个节点
插入 #

首先使用查找算法尝试找到大于 searchKey 的元素,不同的是使用 update[i] 记录了每个链表小于 searchKey 的最后一个元素。
- 如果找到,直接更新 value 为
newValue
否则执行插入流程
- 随机生成一个 level 高度,我们记为
new_level - 当前高度记为
cur_level, 如果new_level > cur_level, skiplist 需要增长,将cur_level +1 -> new_level的 header 记录在update[i]中,更新cur_level = new_level - 创建一个新的
Node - 最后,每个
1 -> cur_level,update[i]作为前驱节点将新Node链接起来
例如插入图3中的 17
update[i]最终记录了{update[4] = 6, update[3] = 6, update[2] = 9, update[1] = 12}这些前驱节点- 随机生成的
randomLevel()小于当前 skiplist 的高度 - 最后将前驱节点和 17 链接起来完成。
删除 #
删除通过查找算法找到要删除的 searchKey,如果没有找到什么也不做。

如果可以找到,记为 x
update[i]记录了searchKey的前驱,摘掉1 -> cur_level中每个链接的x,简单的指针链接- 释放
x的内存 - 最后,看一看 skiplist 高度是否可以降低:如果某一层存在一个空的链表
一些理论的东西 #
MIT 的 6.046j 给出了 skiplist 算法的推导过程, skiplist 的复杂度为 $O(lgn) = O(log_{1/p}n) * (1/p), \text {p is constant}$
leveldb memtable 实现 #
Memtableclass 持有arena_和table_对象的所有权,table_就是 skiplist 的 typedef。Memtable不允许隐式拷贝构造和拷贝复制,允许拷贝指针并手动引用计数管理
class MemTable {
public:
// MemTables are reference counted. The initial reference count
// is zero and the caller must call Ref() at least once.
explicit MemTable(const InternalKeyComparator& comparator);
MemTable(const MemTable&) = delete;
MemTable& operator=(const MemTable&) = delete;
// Increase reference count.
void Ref() { ++refs_; }
// Drop reference count. Delete if no more references exist.
void Unref() {
--refs_;
assert(refs_ >= 0);
if (refs_ <= 0) {
delete this;
}
}
// Returns an estimate of the number of bytes of data in use by this
// data structure. It is safe to call when MemTable is being modified.
size_t ApproximateMemoryUsage();
// Return an iterator that yields the contents of the memtable.
//
// The caller must ensure that the underlying MemTable remains live
// while the returned iterator is live. The keys returned by this
// iterator are internal keys encoded by AppendInternalKey in the
// db/format.{h,cc} module.
Iterator* NewIterator();
// Add an entry into memtable that maps key to value at the
// specified sequence number and with the specified type.
// Typically value will be empty if type==kTypeDeletion.
void Add(SequenceNumber seq, ValueType type, const Slice& key,
const Slice& value);
// If memtable contains a value for key, store it in *value and return true.
// If memtable contains a deletion for key, store a NotFound() error
// in *status and return true.
// Else, return false.
bool Get(const LookupKey& key, std::string* value, Status* s);
private:
friend class MemTableIterator;
friend class MemTableBackwardIterator;
struct KeyComparator {
const InternalKeyComparator comparator;
explicit KeyComparator(const InternalKeyComparator& c) : comparator(c) {}
int operator()(const char* a, const char* b) const;
};
// SkipList 类型别名
typedef SkipList<const char*, KeyComparator> Table;
~MemTable(); // Private since only Unref() should be used to delete it
KeyComparator comparator_;
int refs_;
Arena arena_;
Table table_;
};
初始化 #
// vim db/memtable.cc +21
MemTable::MemTable(const InternalKeyComparator& comparator)
: comparator_(comparator), refs_(0), table_(comparator_, &arena_) {}
可以看到,arena 和跳表共享。
添加 key/value #
leveldb 将 key/value 编码为一个 bytes 数组作为 key 插入到跳表,对 key 的比较通过 comparator 解码出 key 进行比较,如下
+-------------------+----------+---------------+---------------------+-------------------+
| key len (4 bytes) | key data | tag (1 bytes) | value len (4 bytes) | value data |
+-------------------+----------+---------------+---------------------+-------------------+
Add 方法主要打包 key/value 到 Arena 分配的 buf 中
// vim db/memtable.cc +76
void MemTable::Add(SequenceNumber s, ValueType type, const Slice& key,
const Slice& value) {
// Format of an entry is concatenation of:
// key_size : varint32 of internal_key.size()
// key bytes : char[internal_key.size()]
// tag : uint64((sequence << 8) | type)
// value_size : varint32 of value.size()
// value bytes : char[value.size()]
size_t key_size = key.size();
size_t val_size = value.size();
size_t internal_key_size = key_size + 8;
const size_t encoded_len = VarintLength(internal_key_size) +
internal_key_size + VarintLength(val_size) +
val_size;
char* buf = arena_.Allocate(encoded_len);
char* p = EncodeVarint32(buf, internal_key_size);
std::memcpy(p, key.data(), key_size);
p += key_size;
EncodeFixed64(p, (s << 8) | type);
p += 8;
p = EncodeVarint32(p, val_size);
std::memcpy(p, value.data(), val_size);
assert(p + val_size == buf + encoded_len);
table_.Insert(buf);
}
查找 key #
Seek 调用跳表的查找方法,如果找到并且 key 没有被标记删除则拷贝数据到 vlue
// vim db/memtable.cc +102
bool MemTable::Get(const LookupKey& key, std::string* value, Status* s) {
Slice memkey = key.memtable_key();
Table::Iterator iter(&table_);
iter.Seek(memkey.data());
if (iter.Valid()) {
// entry format is:
// klength varint32
// userkey char[klength]
// tag uint64
// vlength varint32
// value char[vlength]
// Check that it belongs to same user key. We do not check the
// sequence number since the Seek() call above should have skipped
// all entries with overly large sequence numbers.
const char* entry = iter.key();
uint32_t key_length;
const char* key_ptr = GetVarint32Ptr(entry, entry + 5, &key_length);
if (comparator_.comparator.user_comparator()->Compare(
Slice(key_ptr, key_length - 8), key.user_key()) == 0) {
// Correct user key
const uint64_t tag = DecodeFixed64(key_ptr + key_length - 8);
switch (static_cast<ValueType>(tag & 0xff)) {
case kTypeValue: {
Slice v = GetLengthPrefixedSlice(key_ptr + key_length);
value->assign(v.data(), v.size());
return true;
}
case kTypeDeletion:
*s = Status::NotFound(Slice());
return true;
}
}
}
return false;
}
leveldb skiplist 实现 #
内存布局 #
Node 表示 skiplist 的节点,是一个内部类,结构上表示为一个多级链表,通过索引访问每一层
- Key 和 Comparator 都是模板类型
next_是原子变量的指针,表示跳表的高度,next_[i]表示第i层的链表。next_默认初始了最底层next_[0]的链表。
// vim db/skiplist.h +142
// Implementation details follow
template <typename Key, class Comparator>
struct SkipList<Key, Comparator>::Node {
explicit Node(const Key& k) : key(k) {}
Key const key;
// Array of length equal to the node height. next_[0] is lowest level link.
std::atomic<Node*> next_[1];
};
SkipList 默认 kMaxHeight 高度(12层)
max_height_是一个 int 型原子变量rnd_用于生成随机数
// vim db/skiplist.h +45
template <typename Key, class Comparator>
class SkipList {
private:
struct Node;
class Iterator { /*...*/ }
private:
enum { kMaxHeight = 12 };
// Immutable after construction
Comparator const compare_;
Arena* const arena_; // Arena used for allocations of nodes
Node* const head_;
// Modified only by Insert(). Read racily by readers, but stale
// values are ok.
std::atomic<int> max_height_; // Height of the entire list
// Read/written only by Insert().
Random rnd_;
};
初始化 #
- 初始化各个数据成员
- 设置每层链表
head_next 指针为空
// vim db/skiplist.h +325
template <typename Key, class Comparator>
SkipList<Key, Comparator>::SkipList(Comparator cmp, Arena* arena)
: compare_(cmp),
arena_(arena),
head_(NewNode(0 /* any key will do */, kMaxHeight)),
max_height_(1),
rnd_(0xdeadbeef) {
for (int i = 0; i < kMaxHeight; i++) {
head_->SetNext(i, nullptr);
}
}
查找 #
FindGreaterOrEqual 查找大于或者等于 key 的节点,prev 保存每一层的前驱节点,即小于 key 的节点
- 流程和原始论文算法一致
- 不同之处,原始论文提供的查找算法伪代码没有
prev,这里为了将查找、插入共用一个代码而进行了归一化处理
// vim db/skiplist.h +255
template <typename Key, class Comparator>
bool SkipList<Key, Comparator>::KeyIsAfterNode(const Key& key, Node* n) const {
// null n is considered infinite
return (n != nullptr) && (compare_(n->key, key) < 0);
}
template <typename Key, class Comparator>
typename SkipList<Key, Comparator>::Node*
SkipList<Key, Comparator>::FindGreaterOrEqual(const Key& key,
Node** prev) const {
Node* x = head_;
int level = GetMaxHeight() - 1;
while (true) {
Node* next = x->Next(level);
if (KeyIsAfterNode(key, next)) {
// Keep searching in this list
x = next;
} else {
if (prev != nullptr) prev[level] = x;
if (level == 0) {
return next;
} else {
// Switch to next list
level--;
}
}
}
}
比较规则实际上由 IternalKeyComparator 实现
- 使用用户自定义的
user_comparator优先比较 key 是否相等 - 如果 key 不相等则比较 SN,SN 越小 key 越大
// vim db/dbformat.cc +47
int InternalKeyComparator::Compare(const Slice& akey, const Slice& bkey) const {
// Order by:
// increasing user key (according to user-supplied comparator)
// decreasing sequence number
// decreasing type (though sequence# should be enough to disambiguate)
int r = user_comparator_->Compare(ExtractUserKey(akey), ExtractUserKey(bkey));
if (r == 0) {
const uint64_t anum = DecodeFixed64(akey.data() + akey.size() - 8);
const uint64_t bnum = DecodeFixed64(bkey.data() + bkey.size() - 8);
if (anum > bnum) {
r = -1;
} else if (anum < bnum) {
r = +1;
}
}
return r;
}
其他一些方法
FindLessThanFindLast
插入 #
FindGreaterOrEqual找到插入的位置,insert 不涉及更新,leveldb 更新作为一个新 key 插入- 随机生成高度并将新的 x 链接起来
template <typename Key, class Comparator>
void SkipList<Key, Comparator>::Insert(const Key& key) {
// TODO(opt): We can use a barrier-free variant of FindGreaterOrEqual()
// here since Insert() is externally synchronized.
Node* prev[kMaxHeight];
Node* x = FindGreaterOrEqual(key, prev);
// Our data structure does not allow duplicate insertion
assert(x == nullptr || !Equal(key, x->key));
int height = RandomHeight();
if (height > GetMaxHeight()) {
for (int i = GetMaxHeight(); i < height; i++) {
prev[i] = head_;
}
// It is ok to mutate max_height_ without any synchronization
// with concurrent readers. A concurrent reader that observes
// the new value of max_height_ will see either the old value of
// new level pointers from head_ (nullptr), or a new value set in
// the loop below. In the former case the reader will
// immediately drop to the next level since nullptr sorts after all
// keys. In the latter case the reader will use the new node.
max_height_.store(height, std::memory_order_relaxeded);
}
x = NewNode(key, height);
for (int i = 0; i < height; i++) {
// NoBarrier_SetNext() suffices since we will add a barrier when
// we publish a pointer to "x" in prev[i].
x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i));
prev[i]->SetNext(i, x);
}
}
NewNode 创建新节点,通过 arena_ 分配内存:节点对象本身大小 + height 个原子指针
// vim db/skiplist.h
template <typename Key, class Comparator>
typename SkipList<Key, Comparator>::Node* SkipList<Key, Comparator>::NewNode(
const Key& key, int height) {
char* const node_memory = arena_->AllocateAligned(
sizeof(Node) + sizeof(std::atomic<Node*>) * (height - 1));
return new (node_memory) Node(key);
}
随机数生成器 #
迭代器 #
迭代器是 Skiplist class 的内部类
// vim db/skiplist.h +60
// Iteration over the contents of a skip list
class Iterator {
public:
// Initialize an iterator over the specified list.
// The returned iterator is not valid.
explicit Iterator(const SkipList* list);
// Returns true iff the iterator is positioned at a valid node.
bool Valid() const;
// Returns the key at the current position.
// REQUIRES: Valid()
const Key& key() const;
// Advances to the next position.
// REQUIRES: Valid()
void Next();
// Advances to the previous position.
// REQUIRES: Valid()
void Prev();
// Advance to the first entry with a key >= target
void Seek(const Key& target);
// Position at the first entry in list.
// Final state of iterator is Valid() iff list is not empty.
void SeekToFirst();
// Position at the last entry in list.
// Final state of iterator is Valid() iff list is not empty.
void SeekToLast();
private:
const SkipList* list_;
Node* node_;
// Intentionally copyable
};
Seek 移动到某个位置,然后在这个位置 Next 遍历,如果不调用 Seek, Next 实际上直接对最底层的链表进行遍历,因为跳表所有数据保存在最底层,上层的都是索引(guard)。
// vim db/skiplist.h +221
template <typename Key, class Comparator>
inline void SkipList<Key, Comparator>::Iterator::Seek(const Key& target) {
node_ = list_->FindGreaterOrEqual(target, nullptr);
}
// vim db/skiplist.h +204
template <typename Key, class Comparator>
inline void SkipList<Key, Comparator>::Iterator::Next() {
assert(Valid());
node_ = node_->Next(0);
}
并发安全 #
leveldb 的跳表是线程安全的,由于 leveldb 是没有并发 writer 的,因此要处理的是并发 reader 和 single-writer 的问题。所以确切的说是 single-writer + concurrent-reader 安全的。
实现上并且没有使用锁,而是选择了原子变量,C++ 原子变量核心是选择内存序,leveldb 使用三种内存序进行同步
- 获取-释放(acquire-release)
- 对成对的读写线程起到同步作用,前一个线程写出 (memory_order_release) 由后一个线程读到 (memory_order_require)
- 内存顺序可传递,A 在 B 之前,B 在 C 之前,则 A 一定在 C 之前
- 宽松(relaxed)
- 同一个线程内,对 `memory_order_relaxede 变量访问不会被重排
- 对多线程不提供任何保证
一般的,我们通常会使用 acquire-release + relaxed 构造一种同步关系,在 leveldb 中叫 barrier。
回到代码
// vim db/skiplist.h +102
inline int GetMaxHeight() const {
return max_height_.load(std::memory_order_relaxeded);
}
// vim db/skiplist.h +151
Node* Next(int n) {
assert(n >= 0);
// Use an 'acquire load' so that we observe a fully initialized
// version of the returned Node.
return next_[n].load(std::memory_order_acquire);
}
// vim db/skiplist.h +157
void SetNext(int n, Node* x) {
assert(n >= 0);
// Use a 'release store' so that anybody who reads through this
// pointer observes a fully initialized version of the inserted node.
next_[n].store(x, std::memory_order_release);
}
// No-barrier variants that can be safely used in a few locations.
Node* NoBarrier_Next(int n) {
assert(n >= 0);
return next_[n].load(std::memory_order_relaxeded);
}
void NoBarrier_SetNext(int n, Node* x) {
assert(n >= 0);
next_[n].store(x, std::memory_order_relaxeded);
}
-
max_height_和next_是原子变量// vim db/skiplist.h +134 // Modified only by Insert(). Read racily by readers, but stale // values are ok. std::atomic<int> max_height_; // Height of the entire list// vim db/skiplist.h +175 // Array of length equal to the node height. next_[0] is lowest level link. std::atomic<Node*> next_[1]; -
查找
max_height_使用load(memory_order_relaxed),next_使用load(memory_order_acquire)// vim db/skiplist.h +263 int level = GetMaxHeight() - 1; while (true) { Node* next = x->Next(level); -
插入
max_height_使用store(memory_order_relaxed),next_则有些复杂// vim db/skiplist.h +349 // It is ok to mutate max_height_ without any synchronization // with concurrent readers. A concurrent reader that observes // the new value of max_height_ will see either the old value of // new level pointers from head_ (nullptr), or a new value set in // the loop below. In the former case the reader will // immediately drop to the next level since nullptr sorts after all // keys. In the latter case the reader will use the new node. max_height_.store(height, std::memory_order_relaxeded);- 新值
x需要在每一层通过prev[i]链接起来 - 新值 x 设置下一层到每一层时使用
x.next_.store(memory_order_relaxed, prev[i].next_.load(memory_order_relaxed))不保证任何顺序 - 但是当链接完成时,通过
prev[i].next_.store(memory_order_release)发布 - 这样保证
next_.load(memory_order_acquire)时中间步骤 x 不会被看到
// vim db/skiplist.h +359 x = NewNode(key, height); for (int i = 0; i < height; i++) { // NoBarrier_SetNext() suffices since we will add a barrier when // we publish a pointer to "x" in prev[i]. x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i)); prev[i]->SetNext(i, x); } - 新值
Reader 从高层到底层访问 Next() ,Writer 从低层到高层发布 SetNext()
- 这意味着,如果 reader 在 i 层可以看到 x,那么根据 acquire-release 的可传递性,在 i - 1 也一定可以看到 x
- 一旦最底层的
SetNext发布,意味着数据写入成功- 因为最底层之上的都是 guard,只影响查找效率,不影响查找正确性(简单来说我明明写入一个 x,但之后的 reader 看不到)
- 在这之前结束的 reader 看不到 x,正在进行(还没有跳到最底层)或之后的 reader 一定可以看到 x
这个性质保证 max_height_ 不需要任何同步,只要 relax 就可以
- 如果读到新的 height,但新的 height 这一层的
head_还没有设置 x,因此会读到nullptr- 根据查找定义,
nullptr会跳到下一层,如果下一层还没有读到 x,就继续跳到下一层,以此类推 - 如果最底层没有看到 x,说明查找在写入之前,即使读到发布的 height,也不影响正确性
- 根据查找定义,
- 如果在 height 或者跳表最底层读到了x,则看到了新值