SSTABLE #
在原始的 LSM 论文中, 每个 level 是一个磁盘组件 (sstable), 这样的缺点是每当合并时开销比较大, 论文中提到了一种滚动合并的方式, 但这种方式实现起来复杂度较高.
leveldb 采用了分区解决上面的问题, leveldb 把每个 level 的磁盘组件物理商划分为多个固定大小的分区, 每个 level 包含多个磁盘组件.
分区具有很多优势, 包括
- 将原本一个大的磁盘组件的合并分为多个小的组件合并, 限制每个合并的时间和创新新组件所需的文件大小
- 分区对于顺序写的工作负载友好, 基本上不需要合并, 因几乎不存在重叠, 实现上可以利用这一点进行优化
文件格式 #
-
存放在 db 目录下的
*.ldb文件 -
默认每个文件最大 2MB 超过这个值切换一个新的文件
但这个值不是硬限制, 只是一个参考值. 例如 memtable 默认 4MB 会进行 compaction 到 level-0, 如果从 level-0 compaction 到 level-1 时没有重叠, 按照优化, 这个 4MB 的文件不会改动.
-
每个 level 可以包含多个文件, 每个 level 可以放置的最大数据为 $10^i$
例如 level=2 时, $i=2, 10^2 = 100\text{Mb}$, 约为 50个文件.
-
每个文件按照 sstable 格式进行编码
-rw-r--r-- 1 1.8M Jul 5 11:53 000005.ldb
-rw-r--r-- 1 2.1M Jul 5 11:53 000016.ldb
-rw-r--r-- 1 2.1M Jul 5 11:53 000017.ldb
-rw-r--r-- 1 2.1M Jul 5 11:53 000018.ldb
-rw-r--r-- 1 2.1M Jul 5 11:53 000019.ldb
-rw-r--r-- 1 2.1M Jul 5 11:53 000029.ldb
-rw-r--r-- 1 2.1M Jul 5 11:53 000030.ldb
-rw-r--r-- 1 2.1M Jul 5 11:53 000031.ldb
-rw-r--r-- 1 2.1M Jul 5 11:53 000032.ldb
-rw-r--r-- 1 1.9M Jul 5 11:53 000034.ldb
-rw-r--r-- 1 917K Jul 5 11:53 000035.ldb
-rw-r--r-- 1 2.1M Jul 5 11:53 000036.ldb
-rw-r--r-- 1 2.1M Jul 5 11:53 000037.ldb
-rw-r--r-- 1 671K Jul 5 11:53 000038.ldb
-rw-r--r-- 1 1.9M Jul 5 11:53 000040.ldb
布局 #
整体分为数据段和元数据段:
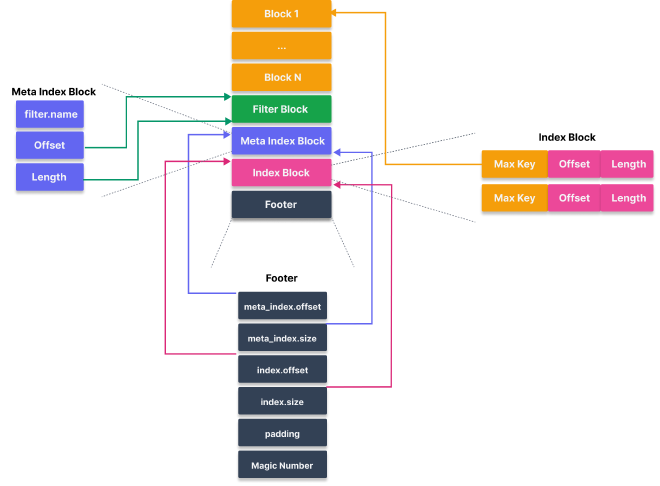
数据段由多个 data block 组成
- 存储 key/value 数据对, 默认大小为 4KB,
- 数据按照 key 排序, 多个 data block 之间的数据也是排序的, 即
data_block[i].last_key < data_block[i+1].first_key
元数据段包括
- filter block: 为 data block 存储布隆过滤器内容, 可选的 (默认开启)
- meta index block: 用来定位 filter block, 一个 sstable 只有一个
- index block: 用来索引和定位 data block, index block 中的每个 entry 索引一个 data block
- footer: 定位 meta index block 和 index block
数据段和元数据段之间的关系:
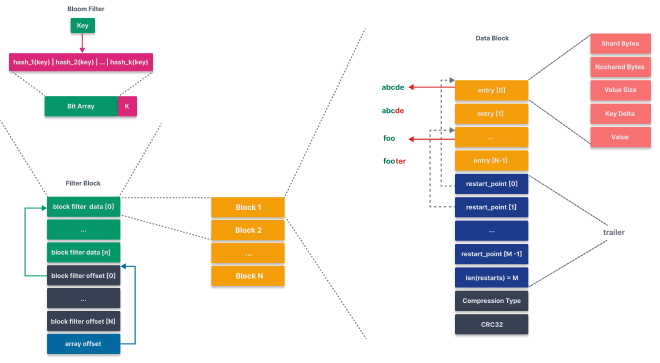
Data Block #
data block 由三部分内容组成
- entries: 存储 key/value 数据, 根据 key 排序
- restarts: 记录了前缀压缩编码信息
- trailer: 记录数据的压缩类型和 crc 校验和.
因为 key 有序, 可以很自然的利用前缀压缩: 每个 key 只存储和上一个 key 不共享的部分, 并记录共享部分的长度.
entry 格式为:
+-----------+-----------+--------------+-------------+-------------+
| shard | unshard | value size | unshard key | value |
+-----------+-----------+--------------+-------------+-------------+
每当间隔 16 个 key/value 时, 新的 key 不会进行编码, 而是记录一个完整的 key, 并基于这个 key 继续按照前面的方式压缩. 这个 key 所在的位置被记录为 restart point.
设计 restart point 的目的在于加速查重过程, 可以将 restart point 看作 skiplist 中的 guard, 首先在 restart point 层定位 key 所在范围, 然后在该范围中进行查找.
Filter Block #
filter block 存储 data block 的过滤内容, filter block 包括
- filter content
- filter offset
- array offset
- base lg
filter content
- 存储 data block 的过滤数据, 默认 bloom filter 编码后的 bit array.
- 默认每 2KB data block 数据生成一个 filter content, 由于每个 data block 4KB, 经过压缩之后可能小于 2KB, 因此 filter content 可能包含多个 data block 的数据.
filter offset
- 存储每个 filter content 的头部位置
- 读取
filter_content[i]只需要读取(filter_offset[i], filter_offset[i+1])就可以得到 content 的开始和结束为止,
array offset
- 记录 filter offset 数量
+--------------------+
+->| filter content [0] |
| +--------------------+
| | filter content [1] |
| +--------------------+
| | filter content [2] |
| +--------------------+
| | ... |
| +--------------------+
| | filter content [N] |
| +--------------------+
+--| filter offset[0] |<-+
+--------------------+ |
| filter offset[1] | |
+--------------------+ |
| ... | |
+--------------------+ |
| filter offset[N] | |
+--------------------+ |
| array_offset = N |--+
+--------------------+
| base_lg |
+--------------------+
Index Block #
index block 由多个 entry 组成,每个 entry 索引一个 data block
- 记录 data block 的 last_key,也相当于 max key
- 记录 data block 的 offset 和 size,用于读取 data block
Footer #
footer 存储 meta index block 和 index block 的 offset 和 size,用于读取这两个数据段的信息。footer 还会在尾部进行一些填充。
格式特点 #
-
Append-only
- 写入数据是预先排好序的,准确的说从 memtable 开始就是有序的
- 没有 header 只有 footer,
- 写入数据不可变,不支持 in-place (read-modify-write)更新,使用 out-place 覆盖更新
对闪存友好,提高寿命, 因为一个 block 上反复写会把闪存写穿。
- 可以简化分布式文件系统实现,提高分布式文件系统写入的性能
-
没有 header 只有 footer,原因在于
- 如果需要 header 需要在 data block 写完才能生成 header,然后需要一次随机写插入到 header
- 如果需要 header,data block 和 index block 需要在构建 是stable 时保留在内存中。而没有 header 的情况下,只需要 data block 和 index block 在内存中,写一个 data block 编码一个 index block,最后整个 sstable 写完。
-
restart point 对 data block 做了空间和查找时间的 trade-off
- 如果 restart point 太大,查找比较麻烦
- 如果 restart point 太小,压缩效果不好
-
读取需要 seek
- 但 sort 使得 seek 次数很好
- 闪存对随机读友好,所以闪存对 leveldb 很友好
-
两层索引
- 通过 index block 定位 data block,data block 中根据 restart point 定位 entry
- index block 的设计使得不需要读取整个 sstable 来定位 data block,只需要读入一个 index block 和 一个 data block 到内存中
-
对顺序扫描的 workload 友好
- 读取 index block 到内存
- 根据 index block 顺序读 data block
-
没有考虑对 OLAP workloads 优化
- 没有记录诸如每个 sstable 多少个 block 之类信息
-
可调性
实现 #
核心数据结构 #
BlockBuilder #
// vim table/block_builder.h +17
class BlockBuilder {
private:
const Options* options_;
std::string buffer_; // Destination buffer
std::vector<uint32_t> restarts_; // Restart points
int counter_; // Number of entries emitted since restart
bool finished_; // Has Finish() been called?
std::string last_key_;
};
buffer_存储在构建过程中整个 data block 数据.restarts_记录每个restart point在buffer_中的位置, 其中第一个restart point为 0.counter_记录了当前 restart point 数量, 默认每 16 个 key/value 重新计算下一个 restart point.
Add 使用前缀压缩编码 key/value 数据到 data block
- 计算 key 和上一个 key 共享前缀进行前缀压缩, 然后记录 restart point 到
restarts_ - 编码 shared 信息
- 将前缀编码信息 + 数据写入到
buffer_
// vim table/block_builder.cc +71
void BlockBuilder::Add(const Slice& key, const Slice& value) {
Slice last_key_piece(last_key_);
assert(!finished_);
assert(counter_ <= options_->block_restart_interval);
assert(buffer_.empty() // No values yet?
|| options_->comparator->Compare(key, last_key_piece) > 0);
size_t shared = 0;
if (counter_ < options_->block_restart_interval) {
// See how much sharing to do with previous string
const size_t min_length = std::min(last_key_piece.size(), key.size());
while ((shared < min_length) && (last_key_piece[shared] == key[shared])) {
shared++;
}
} else {
// Restart compression
restarts_.push_back(buffer_.size());
counter_ = 0;
}
const size_t non_shared = key.size() - shared;
// Add "<shared><non_shared><value_size>" to buffer_
PutVarint32(&buffer_, shared);
PutVarint32(&buffer_, non_shared);
PutVarint32(&buffer_, value.size());
// Add string delta to buffer_ followed by value
buffer_.append(key.data() + shared, non_shared);
buffer_.append(value.data(), value.size());
// Update state
last_key_.resize(shared);
last_key_.append(key.data() + shared, non_shared);
assert(Slice(last_key_) == key);
counter_++;
}
Finish 完成 data block 编码, 返回编码后整个 data block 段数据
- 根据
restarts_将restart_point编码到buffer_尾部 - 写入
restart_point数量到buffer_尾部
Slice BlockBuilder::Finish() {
// Append restart array
for (size_t i = 0; i < restarts_.size(); i++) {
PutFixed32(&buffer_, restarts_[i]);
}
PutFixed32(&buffer_, restarts_.size());
finished_ = true;
return Slice(buffer_);
}
FilterBlockBuilder #
FilterBlockBuilder 用于构造 filter block,维护了构造过程所需的数据成员。
// vim table/filter_block.cc +30
class FilterBlockBuilder {
public:
explicit FilterBlockBuilder(const FilterPolicy*);
FilterBlockBuilder(const FilterBlockBuilder&) = delete;
FilterBlockBuilder& operator=(const FilterBlockBuilder&) = delete;
void StartBlock(uint64_t block_offset);
void AddKey(const Slice& key);
Slice Finish();
private:
void GenerateFilter();
const FilterPolicy* policy_;
std::string keys_; // Flattened key contents
std::vector<size_t> start_; // Starting index in keys_ of each key
std::string result_; // Filter data computed so far
std::vector<Slice> tmp_keys_; // policy_->CreateFilter() argument
std::vector<uint32_t> filter_offsets_;
};
-
FilterBlockBuilder将添加的 key 铺平为一个连续的字节数组keys_,start_数组维护了每个原始 key 在keys_中开始的位置。
-
result_维护了整个 filter 的内容,包括多个 filter entry,filter_offsets_指向每个 filter entry 的起始位置。
BlockHandle #
因为 sstable 中有很多数据块需要编码 size 和 offset, BlockHandle 主要作用是根据内容编码这些信息。
// vim table/format.h +21
// BlockHandle is a pointer to the extent of a file that stores a data
// block or a meta block.
class BlockHandle {
public:
// Maximum encoding length of a BlockHandle
enum { kMaxEncodedLength = 10 + 10 };
BlockHandle();
// The offset of the block in the file.
uint64_t offset() const { return offset_; }
void set_offset(uint64_t offset) { offset_ = offset; }
// The size of the stored block
uint64_t size() const { return size_; }
void set_size(uint64_t size) { size_ = size; }
void EncodeTo(std::string* dst) const;
Status DecodeFrom(Slice* input);
private:
uint64_t offset_;
uint64_t size_;
};
EncodeTo 将 offset_ 和 size_ 打包到 dst 尾部。
// vim table/format.cc +6
void BlockHandle::EncodeTo(std::string* dst) const {
// Sanity check that all fields have been set
assert(offset_ != ~static_cast<uint64_t>(0));
assert(size_ != ~static_cast<uint64_t>(0));
PutVarint64(dst, offset_);
PutVarint64(dst, size_);
}
Footer #
Footer 用于编码 sstable footer 信息。footer 需要编码 meta index 和 index block 的 offset 和 size,使用 BlockHandle 表示。
// vim table/format.h +46
// Footer encapsulates the fixed information stored at the tail
// end of every table file.
class Footer {
public:
// Encoded length of a Footer. Note that the serialization of a
// Footer will always occupy exactly this many bytes. It consists
// of two block handles and a magic number.
enum { kEncodedLength = 2 * BlockHandle::kMaxEncodedLength + 8 };
void EncodeTo(std::string* dst) const;
private:
BlockHandle metaindex_handle_;
BlockHandle index_handle_;
};
EncodeTo 将 footer 打包到 dst 尾部
// vim table/format.cc +31
void Footer::EncodeTo(std::string* dst) const {
const size_t original_size = dst->size();
metaindex_handle_.EncodeTo(dst);
index_handle_.EncodeTo(dst);
dst->resize(2 * BlockHandle::kMaxEncodedLength); // Padding
PutFixed32(dst, static_cast<uint32_t>(kTableMagicNumber & 0xffffffffu));
PutFixed32(dst, static_cast<uint32_t>(kTableMagicNumber >> 32));
assert(dst->size() == original_size + kEncodedLength);
(void)original_size; // Disable unused variable warning.
}
- 编码 meta index 和 index block 的 offset 和 size
- 填充 padding
- 写入 magic number
写入 sstable #
sstable 格式打包过程为:
- 打开一个文件
- 写入数据段
- 关闭文件时添加元数据段
初始化 TableBuilder #
TableBuilder 实现了 sstable 打包,核心数据成员由 Rep 表示,使用了桥接设计模式。
桥接模式是将抽象部分与它的实现部分分离,使它们都可以独立地变化。它是一种对象结构型模式,又称为柄体(Handle and Body)模式或接口(Interfce)模式。
struct TableBuilder::Rep {
Options options;
Options index_block_options;
WritableFile* file;
uint64_t offset;
Status status;
BlockBuilder data_block;
BlockBuilder index_block;
std::string last_key;
int64_t num_entries;
bool closed; // Either Finish() or Abandon() has been called.
FilterBlockBuilder* filter_block;
// We do not emit the index entry for a block until we have seen the
// first key for the next data block. This allows us to use shorter
// keys in the index block. For example, consider a block boundary
// between the keys "the quick brown fox" and "the who". We can use
// "the r" as the key for the index block entry since it is >= all
// entries in the first block and < all entries in subsequent
// blocks.
//
// Invariant: r->pending_index_entry is true only if data_block is empty.
bool pending_index_entry;
BlockHandle pending_handle; // Handle to add to index block
std::string compressed_output;
};
Rep 大部分数据成员比较好理解。其中 offset 表示 sstable 的段内偏移,当构建 sstable 时初始化为 0。
TableBuilder 初始化 Rep
TableBuilder::TableBuilder(const Options& options, WritableFile* file)
: rep_(new Rep(options, file)) {
if (rep_->filter_block != nullptr) {
rep_->filter_block->StartBlock(0);
}
}
Rep(const Options& opt, WritableFile* f)
: options(opt),
index_block_options(opt),
file(f),
offset(0),
data_block(&options),
index_block(&index_block_options),
num_entries(0),
closed(false),
filter_block(opt.filter_policy == nullptr
? nullptr
: new FilterBlockBuilder(opt.filter_policy)),
pending_index_entry(false) {
index_block_options.block_restart_interval = 1;
}
写入数据 #
调用 Add 添加 key/value
- key 添加到 filter block
- key/value 添加到 data block
- 如果当 block size 超过选项配置的大小时需要进行 flush
对于 pending_index_entry 的作用, 放到后面解释.
// vim table/table_builder.cc +94
void TableBuilder::Add(const Slice& key, const Slice& value) {
Rep* r = rep_;
assert(!r->closed);
if (!ok()) return;
if (r->num_entries > 0) {
assert(r->options.comparator->Compare(key, Slice(r->last_key)) > 0);
}
if (r->pending_index_entry) {
assert(r->data_block.empty());
r->options.comparator->FindShortestSeparator(&r->last_key, key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
if (r->filter_block != nullptr) {
r->filter_block->AddKey(key);
}
r->last_key.assign(key.data(), key.size());
r->num_entries++;
r->data_block.Add(key, value);
const size_t estimated_block_size = r->data_block.CurrentSizeEstimate();
if (estimated_block_size >= r->options.block_size) {
Flush();
}
}
Flush 将 data block 追加写入文件,并为该 data block 生成 filter block 内容
// vim table/table_builder.cc +125
void TableBuilder::Flush() {
Rep* r = rep_;
assert(!r->closed);
if (!ok()) return;
if (r->data_block.empty()) return;
assert(!r->pending_index_entry);
WriteBlock(&r->data_block, &r->pending_handle);
if (ok()) {
r->pending_index_entry = true;
r->status = r->file->Flush();
}
if (r->filter_block != nullptr) {
r->filter_block->StartBlock(r->offset);
}
}
WriteBlock 首先调用 BlockBuilder::Finish() 编码 data block 内容,如果需要压缩则使用 snappy 压缩编码后的 data block, 最后通过 WriteRawBlock 将 data block 内容追加到文件。
// vim table/table_builder.cc +141
void TableBuilder::WriteBlock(BlockBuilder* block, BlockHandle* handle) {
// File format contains a sequence of blocks where each block has:
// block_data: uint8[n]
// type: uint8
// crc: uint32
assert(ok());
Rep* r = rep_;
Slice raw = block->Finish();
Slice block_contents;
CompressionType type = r->options.compression;
// TODO(postrelease): Support more compression options: zlib?
switch (type) {
case kNoCompression:
block_contents = raw;
break;
case kSnappyCompression: {
std::string* compressed = &r->compressed_output;
if (port::Snappy_Compress(raw.data(), raw.size(), compressed) &&
compressed->size() < raw.size() - (raw.size() / 8u)) {
block_contents = *compressed;
} else {
// Snappy not supported, or compressed less than 12.5%, so just
// store uncompressed form
block_contents = raw;
type = kNoCompression;
}
break;
}
case kZstdCompression: {
std::string* compressed = &r->compressed_output;
if (port::Zstd_Compress(r->options.zstd_compression_level, raw.data(),
raw.size(), compressed) &&
compressed->size() < raw.size() - (raw.size() / 8u)) {
block_contents = *compressed;
} else {
// Zstd not supported, or compressed less than 12.5%, so just
// store uncompressed form
block_contents = raw;
type = kNoCompression;
}
break;
}
}
WriteRawBlock(block_contents, type, handle);
r->compressed_output.clear();
block->Reset();
}
WriteRawBlock
- 设置 index block,记录该 data blcok 的 size 和 offset
- 创建 trailer,包括 1byte 压缩类型 (snappy or no) 和 32byte crc 校验和
- data block 数据内容和 trailer 一起追加写到文件,
- 设置 sstable 段内偏移。
// vim table/table_builder.cc +192
void TableBuilder::WriteRawBlock(const Slice& block_contents,
CompressionType type, BlockHandle* handle) {
Rep* r = rep_;
handle->set_offset(r->offset);
handle->set_size(block_contents.size());
r->status = r->file->Append(block_contents);
if (r->status.ok()) {
char trailer[kBlockTrailerSize];
trailer[0] = type;
uint32_t crc = crc32c::Value(block_contents.data(), block_contents.size());
crc = crc32c::Extend(crc, trailer, 1); // Extend crc to cover block type
EncodeFixed32(trailer + 1, crc32c::Mask(crc));
r->status = r->file->Append(Slice(trailer, kBlockTrailerSize));
if (r->status.ok()) {
r->offset += block_contents.size() + kBlockTrailerSize;
}
}
}
写入 filter block 内容 #
Flush 时如果 filter_block 指针不为空,则调用 StartBlock 为 data block 生成 filter content。但需要注意的是
- 每 2KB 的 data block 数据大小创建一个 filter block
- data block 最大约等于 4KB,并且使用 snappy 压缩。所以 一个 data block 可能小于 2KB,这意味着多个 data block 可能对应一个 filter block
// vim table/filter_block.cc +14
// Generate new filter every 2KB of data
static const size_t kFilterBaseLg = 11;
static const size_t kFilterBase = 1 << kFilterBaseLg;
// vim table/filter_block.cc +18
void FilterBlockBuilder::StartBlock(uint64_t block_offset) {
uint64_t filter_index = (block_offset / kFilterBase);
assert(filter_index >= filter_offsets_.size());
while (filter_index > filter_offsets_.size()) {
GenerateFilter();
}
}
上面代码中,filter_index 对应当第 i 个 2KB 数据段,filter_offsets_ 记录有多少个 filter content,如果当前 filter content 数量不满足, 则调用 GenerateFilter 生成新的 filter block。
GenerateFilter
start_记录了每个 filter content 起始位置- 将添加的 keys 拷贝赋值到
tmp_keys_ filter_offsets_记录这个生成的 filter block 内容的起始位置- 基于
tmp_keys_创建 filter 内容(Bloom Filter),写入到result_
// vim table/filter_block.cc +51
void FilterBlockBuilder::GenerateFilter() {
const size_t num_keys = start_.size();
if (num_keys == 0) {
// Fast path if there are no keys for this filter
filter_offsets_.push_back(result_.size());
return;
}
// Make list of keys from flattened key structure
start_.push_back(keys_.size()); // Simplify length computation
tmp_keys_.resize(num_keys);
for (size_t i = 0; i < num_keys; i++) {
const char* base = keys_.data() + start_[i];
size_t length = start_[i + 1] - start_[i];
tmp_keys_[i] = Slice(base, length);
}
// Generate filter for current set of keys and append to result_.
filter_offsets_.push_back(result_.size());
policy_->CreateFilter(&tmp_keys_[0], static_cast<int>(num_keys), &result_);
tmp_keys_.clear();
keys_.clear();
start_.clear();
}
pending_index_entry 作用 #
pending_index_entry 的作用是充当一个优化变量, 允许在上一个 data block 和 下一个 data block 之间的边界为 index block 选择一个更短的 last key。
实现中,每当一个 data block flush 时 pending_index_entry 设置为 true
void TableBuilder::Flush() {
Rep* r = rep_;
assert(!r->closed);
if (!ok()) return;
if (r->data_block.empty()) return;
assert(!r->pending_index_entry);
WriteBlock(&r->data_block, &r->pending_handle);
if (ok()) {
r->pending_index_entry = true;
当调用 Add 再次添加数据时, 也就是遇到下一个 data block 的第一个 key, 此时 pending_index_entry = true, 会向 index block 写入一条数据:
- leveldb 会在上一个 data block 中最大的 key (last_key) 和当前 key 中找到一个最短的
- 同时 flush 时记录了上一个 data block 的 size 和 offset
if (r->pending_index_entry) {
assert(r->data_block.empty());
r->options.comparator->FindShortestSeparator(&r->last_key, key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
生成 sstable #
当数据写完或者文件到达大小限制,调用 Finish 生成 sstable ,代码逻辑比较简单,按照 sstable 格式依次写入 data block 之后的内容
- 将 filter block 内容写入
- 根据 filter block 信息构造 meta index block
- 写入 index block
- 写入 footer
// vim table/table_builder.cc +213
Status TableBuilder::Finish() {
Rep* r = rep_;
Flush();
assert(!r->closed);
r->closed = true;
BlockHandle filter_block_handle, metaindex_block_handle, index_block_handle;
// Write filter block
if (ok() && r->filter_block != nullptr) {
WriteRawBlock(r->filter_block->Finish(), kNoCompression,
&filter_block_handle);
}
// Write metaindex block
if (ok()) {
BlockBuilder meta_index_block(&r->options);
if (r->filter_block != nullptr) {
// Add mapping from "filter.Name" to location of filter data
std::string key = "filter.";
key.append(r->options.filter_policy->Name());
std::string handle_encoding;
filter_block_handle.EncodeTo(&handle_encoding);
meta_index_block.Add(key, handle_encoding);
}
// TODO(postrelease): Add stats and other meta blocks
WriteBlock(&meta_index_block, &metaindex_block_handle);
}
// Write index block
if (ok()) {
if (r->pending_index_entry) {
r->options.comparator->FindShortSuccessor(&r->last_key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
WriteBlock(&r->index_block, &index_block_handle);
}
// Write footer
if (ok()) {
Footer footer;
footer.set_metaindex_handle(metaindex_block_handle);
footer.set_index_handle(index_block_handle);
std::string footer_encoding;
footer.EncodeTo(&footer_encoding);
r->status = r->file->Append(footer_encoding);
if (r->status.ok()) {
r->offset += footer_encoding.size();
}
}
return r->status;
}
读取 sstable #
Open 打开一个 sstable 文件, 按照格式依次读取元数据
- footer
- 根据 footer 读取 index block 和 meta index block
- 根据 meta index block 读取 filter block (如果有)
在 sstable 保持打开的过程中, 通过 Iterator 读取数据
Iterator由 index block 提供