调度 Compaction #
// REQUIRES: mutex_ is held
// REQUIRES: this thread is currently at the front of the writer queue
Status DBImpl::MakeRoomForWrite(bool force) {
mutex_.AssertHeld();
assert(!writers_.empty());
bool allow_delay = !force;
Status s;
while (true) {
if (!bg_error_.ok()) {
// Yield previous error
s = bg_error_;
break;
} else if (allow_delay && versions_->NumLevelFiles(0) >=
config::kL0_SlowdownWritesTrigger) {
// We are getting close to hitting a hard limit on the number of
// L0 files. Rather than delaying a single write by several
// seconds when we hit the hard limit, start delaying each
// individual write by 1ms to reduce latency variance. Also,
// this delay hands over some CPU to the compaction thread in
// case it is sharing the same core as the writer.
mutex_.Unlock();
env_->SleepForMicroseconds(1000);
allow_delay = false; // Do not delay a single write more than once
mutex_.Lock();
} else if (!force &&
(mem_->ApproximateMemoryUsage() <= options_.write_buffer_size)) {
// There is room in current memtable
break;
} else if (imm_ != nullptr) {
// We have filled up the current memtable, but the previous
// one is still being compacted, so we wait.
Log(options_.info_log, "Current memtable full; waiting...\n");
background_work_finished_signal_.Wait();
} else if (versions_->NumLevelFiles(0) >= config::kL0_StopWritesTrigger) {
// There are too many level-0 files.
Log(options_.info_log, "Too many L0 files; waiting...\n");
background_work_finished_signal_.Wait();
} else {
// Attempt to switch to a new memtable and trigger compaction of old
assert(versions_->PrevLogNumber() == 0);
uint64_t new_log_number = versions_->NewFileNumber();
WritableFile* lfile = nullptr;
s = env_->NewWritableFile(LogFileName(dbname_, new_log_number), &lfile);
if (!s.ok()) {
// Avoid chewing through file number space in a tight loop.
versions_->ReuseFileNumber(new_log_number);
break;
}
delete log_;
s = logfile_->Close();
if (!s.ok()) {
// We may have lost some data written to the previous log file.
// Switch to the new log file anyway, but record as a background
// error so we do not attempt any more writes.
//
// We could perhaps attempt to save the memtable corresponding
// to log file and suppress the error if that works, but that
// would add more complexity in a critical code path.
RecordBackgroundError(s);
}
delete logfile_;
logfile_ = lfile;
logfile_number_ = new_log_number;
log_ = new log::Writer(lfile);
imm_ = mem_;
has_imm_.store(true, std::memory_order_release);
mem_ = new MemTable(internal_comparator_);
mem_->Ref();
force = false; // Do not force another compaction if have room
MaybeScheduleCompaction();
}
}
return s;
}
Minor Compaction #
leveldb 写入首先到内存组件, 但写入到内存中组件的大小不能无限增长. Minor compaction 的作用是当 memtable 到达一定大小时, 将 memtable 的数据写入到磁盘组件.
Minor Compaction 对时效性要求非常高, 要尽快的完成, 因为 minor compaction 期间会会阻塞写入. 因此 minor compaction 优先级最高. 当进行minor compaction的时候有major compaction正在进行, 则会首先暂停major compaction.
从高层次来看 触发 minor compaction 后会做以下事情
- 冻结当前的 memtable 和 wal log
- 创建新的 wal log
- 将冻结的 memtable 内容按照 sstable 格式写入到磁盘组件
- 记录版本变更信息
- 删除 wal 日志
- 解除冻结的 memtable
Major Compaction #
作用
- 将不活跃的数据下沉,均衡各个level的数据,保证 read 的性能;
- 合并delete数据,释放磁盘空间,因为leveldb是采用的延迟(标记)删除;
- 合并update的数据,例如put同一个key,新put的会替换旧put的,虽然数据做了update,但是update类似于delete,是采用的延迟(标记)update,实际的update是在compact中完成,并实现空间的释放。
触发方式 #
majory compaction 两种出发方式
- 手动
- 自动
手动触发
- 自身业务比 leveldb 更清楚什么时候可以 compaction
- ceph 使用这种方式
自动触发分为两类
- size compaction.
- seek compaction.
什么时候触发 size compaction
- level 0 文件个数超过
kL0_CompactionTrigger, 默认为 4 - 其他 level 文件大小超过该层最大限制
MaxBytesForLevel
// version_set.cc VersionSet::Finalize
void VersionSet::Finalize(Version* v) {
// Precomputed best level for next compaction
int best_level = -1;
double best_score = -1;
for (int level = 0; level < config::kNumLevels - 1; level++) {
double score;
if (level == 0) {
// We treat level-0 specially by bounding the number of files
// instead of number of bytes for two reasons:
//
// (1) With larger write-buffer sizes, it is nice not to do too
// many level-0 compactions.
//
// (2) The files in level-0 are merged on every read and
// therefore we wish to avoid too many files when the individual
// file size is small (perhaps because of a small write-buffer
// setting, or very high compression ratios, or lots of
// overwrites/deletions).
score = v->files_[level].size() /
static_cast<double>(config::kL0_CompactionTrigger);
} else {
// Compute the ratio of current size to size limit.
const uint64_t level_bytes = TotalFileSize(v->files_[level]);
score =
static_cast<double>(level_bytes) / MaxBytesForLevel(options_, level);
}
if (score > best_score) {
best_level = level;
best_score = score;
}
}
v->compaction_level_ = best_level;
v->compaction_score_ = best_score;
}
- 循环计算积分
- 对于 level-0 来说, 计算出的积分总是大于其他层
- 选择积分最大的层作为 size_compaction 的目标
// version_set.h
static double MaxBytesForLevel(const Options* options, int level) {
// Note: the result for level zero is not really used since we set
// the level-0 compaction threshold based on number of files.
// Result for both level-0 and level-1
double result = 10. * 1048576.0;
while (level > 1) {
result *= 10;
level--;
}
return result;
}
- level-0 和 level-1 最大大小默认 10 MB
- 其他 level-i 为 $10^i$, 例如 $10^2 = 100MB, 10^3=1GB …$ 依此类推
size_comapaction 理解起来比较容器, 简单来说文件到达限制就触发 compaction.
但是 level-0 独立的 case 原因在于: level-0 允许 sstable 互相重叠, 因此如果 level-0 文件太多, 会影响读取效率 (需要搜索每个 sstable).
什么时候触发 seek_compaction
- 查找某个 sstable 未命中次数过多
bool Version::UpdateStats(const GetStats& stats) {
FileMetaData* f = stats.seek_file;
if (f != nullptr) {
f->allowed_seeks--;
if (f->allowed_seeks <= 0 && file_to_compact_ == nullptr) {
file_to_compact_ = f;
file_to_compact_level_ = stats.seek_file_level;
return true;
}
}
return false;
}
if (f->allowed_seeks <= 0 && file_to_compact_ == nullptr)触发seek_compactionallowed_seeks默认为 100, 在 manifest apply 时设置
调用 UpdateStats 的地方
为什么要引入这个 seek_compaction? leveldb 作者给出的解释为
- One seek costs 10ms
- Writing or reading 1MB costs 10ms (100MB/s)
- A compaction of 1MB does 25MB of IO: 1MB read from this level 10-12MB read from next level (boundaries may be misaligned) 10-12MB written to next level This implies that 25 seeks cost the same as the compaction
合并过程 #
两部分
- 选择哪些文件进行合并?
-> PickCompaction vim db/version_set.cc +1252 - 合并选择的文件
-> DoCompactionWork
选择合并的文件 #
选择 level-i 要合并的 sstale #
PickCompaction 选择要合并的文件, 返回 Compaction 包含合并所需的状态
选择 size_compaction 或者 seek_compaction
// vim db/version_set.cc +1252
Compaction* VersionSet::PickCompaction() {
Compaction* c;
int level;
// We prefer compactions triggered by too much data in a level over
// the compactions triggered by seeks.
const bool size_compaction = (current_->compaction_score_ >= 1);
const bool seek_compaction = (current_->file_to_compact_ != nullptr);
size_compaction,根据对应的 level,在该层级中选择一个起始 sstable 作为输入。
- 该层级上一次合并过,
compact_pointer_[level]记录了上一次合并后文件的最大 key,选择第一个大于compact_pointer_[level]的 sstable,否则选择该层级第一个文件 - 如果该层级所有 sstable 都小于
compact_pointer_[level],选择该层级第一个文件
// vim db/version_set.cc +1260
if (size_compaction) {
level = current_->compaction_level_;
assert(level >= 0);
assert(level + 1 < config::kNumLevels);
c = new Compaction(options_, level);
// Pick the first file that comes after compact_pointer_[level]
for (size_t i = 0; i < current_->files_[level].size(); i++) {
FileMetaData* f = current_->files_[level][i];
if (compact_pointer_[level].empty() ||
icmp_.Compare(f->largest.Encode(), compact_pointer_[level]) > 0) {
c->inputs_[0].push_back(f);
break;
}
}
if (c->inputs_[0].empty()) {
// Wrap-around to the beginning of the key space
c->inputs_[0].push_back(current_->files_[level][0]);
}
}
seek compaction 比较简单,因为直接记录了要合并 sstable
// vim db/version_set.cc +1279
} else if (seek_compaction) {
level = current_->file_to_compact_level_;
c = new Compaction(options_, level);
c->inputs_[0].push_back(current_->file_to_compact_);
} else {
return nullptr;
}
c->input_version_ = current_;
c->input_version_->Ref();
特别的,如果是 level-0,由于 level-0 允许存在多个相互重叠的 sstable,所以 level-0 需要选择所有重叠的 sstable 作为输入。
- 计算输入 sstable 的范围
- 根据计算的范围,找到 level-0 中其他与该范围重叠的 sstable 添加到输入文件中
// vim db/version_set.cc +1290
// Files in level 0 may overlap each other, so pick up all overlapping ones
if (level == 0) {
InternalKey smallest, largest;
GetRange(c->inputs_[0], &smallest, &largest);
// Note that the next call will discard the file we placed in
// c->inputs_[0] earlier and replace it with an overlapping set
// which will include the picked file.
current_->GetOverlappingInputs(0, &smallest, &largest, &c->inputs_[0]);
assert(!c->inputs_[0].empty());
}
SetupOtherInputs(c);
return c;
}
GetOverlappingInputs 根据范围获取 level-0 重叠的文件放入 inputs 中
void Version::GetOverlappingInputs(int level, const InternalKey* begin,
const InternalKey* end,
std::vector<FileMetaData*>* inputs) {
assert(level >= 0);
assert(level < config::kNumLevels);
inputs->clear();
Slice user_begin, user_end;
if (begin != nullptr) {
user_begin = begin->user_key();
}
if (end != nullptr) {
user_end = end->user_key();
}
const Comparator* user_cmp = vset_->icmp_.user_comparator();
for (size_t i = 0; i < files_[level].size();) {
FileMetaData* f = files_[level][i++];
const Slice file_start = f->smallest.user_key();
const Slice file_limit = f->largest.user_key();
if (begin != nullptr && user_cmp->Compare(file_limit, user_begin) < 0) {
// "f" is completely before specified range; skip it
} else if (end != nullptr && user_cmp->Compare(file_start, user_end) > 0) {
// "f" is completely after specified range; skip it
} else {
inputs->push_back(f);
if (level == 0) {
// 0级文件可能相互重叠。所以检查新添加的文件是否扩展了范围。如果是,重新开始搜索。
if (begin != nullptr && user_cmp->Compare(file_start, user_begin) < 0) {
user_begin = file_start;
inputs->clear();
i = 0;
} else if (end != nullptr &&
user_cmp->Compare(file_limit, user_end) > 0) {
user_end = file_limit;
inputs->clear();
i = 0;
}
}
}
}
}
- 代码很简单,首先获取 level 的文件列表,遍历所有文件,根据
begin和end找到重叠的 sstable 添加到inputs中 - 对于 level-0 做了特殊处理,level-0 会扩大重叠的范围,并当范围扩大时基于新的范围重新搜索文件列表。
举个例子,下图
- 首先
PickCompaction选择的是 level-0 中[0 - 39]的 sstable,然后以该 sstable 作为GetOverlappingInputs(0, 0, 39, &inputs)参数输入。 - 由于是 level-0 在搜索时最开始的范围为
[0 - 39], 最后更新后的范围为[0 - 105], 于是基于新的范围,level-0 所有与之重叠的 sstable 都加入了进来。
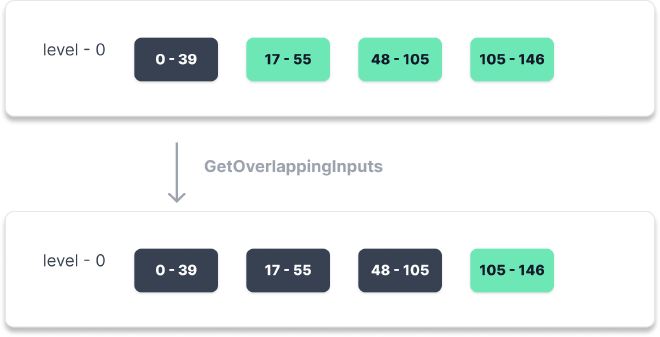
这里隐藏一个 bug,但 leveldb 处理了,你可以先猜一猜会产生什么问题?
上面代码完成了 level-i 文件的选择,也就是 inputs_[0] 中的文件,合并还需要选择 level-i+1 的文件,即 inputs_[1], 由 SetupOtherInputs 完成。
选择 level-i+1 要合并的 sstable #
除了选择 level-i+1 的 sstable, SetupOtherInputs 还有一个 case 就是当选择 level-i+1 的 sstable 之后,在不影响 level-i+1 已选择的 sstable 前提下,根据 level-i+1 的范围再次尝试扩充 level-i 的 sstable。
step1. 处理 level-i 合并文件和该层其他文件边界重叠 #
在上面提到隐藏了一个 bug,在 SetupOtherInputs 进行了处理。具体来说,上图中最后选择的 level-0 [48 - 105] 和 [105 - 146] 存在一个边界 key: 105 重叠,但是 GetOverlappingInputs 并没有选择,假设 level-0 合并到 level-1,随后的 Get(105) 将返回 level-0 对应的 key,这可能不正确。所以,leveldb 通过 AddBoundaryInputs 进行了处理
void VersionSet::SetupOtherInputs(Compaction* c) {
const int level = c->level();
InternalKey smallest, largest;
AddBoundaryInputs(icmp_, current_->files_[level], &c->inputs_[0]);
AddBoundaryInputs 首先在 inputs_[0] 中找到最大的 key。然后通过 FindSmallestBoundaryFile 在该层文件中找到与最大 key 相同的最小 key,也就是边界 key。
如果找到这样的key,inputs_[0] 会将这个边界 key 所在的 sstable 文件加入到 inputs_[0],同时更新最大 key 为这个新加入 sstable 的最大 key。
如上图中,经过 AddBoundaryInputs 处理,最大 key: 105 和 level-0 第 4 个文件的最小 key: 105 边界重叠,因此第 4 个文件会加入到 inputs_[0] 并更新 largest_key=146, 从而避免了 bug。
// vim db/version_set.cc +1346
// Extracts the largest file b1 from |compaction_files| and then searches for a
// b2 in |level_files| for which user_key(u1) = user_key(l2). If it finds such a
// file b2 (known as a boundary file) it adds it to |compaction_files| and then
// searches again using this new upper bound.
//
// If there are two blocks, b1=(l1, u1) and b2=(l2, u2) and
// user_key(u1) = user_key(l2), and if we compact b1 but not b2 then a
// subsequent get operation will yield an incorrect result because it will
// return the record from b2 in level i rather than from b1 because it searches
// level by level for records matching the supplied user key.
//
// parameters:
// in level_files: List of files to search for boundary files.
// in/out compaction_files: List of files to extend by adding boundary files.
void AddBoundaryInputs(const InternalKeyComparator& icmp,
const std::vector<FileMetaData*>& level_files,
std::vector<FileMetaData*>* compaction_files) {
InternalKey largest_key;
// Quick return if compaction_files is empty.
if (!FindLargestKey(icmp, *compaction_files, &largest_key)) {
return;
}
bool continue_searching = true;
while (continue_searching) {
FileMetaData* smallest_boundary_file =
FindSmallestBoundaryFile(icmp, level_files, largest_key);
// If a boundary file was found advance largest_key, otherwise we're done.
if (smallest_boundary_file != NULL) {
compaction_files->push_back(smallest_boundary_file);
largest_key = smallest_boundary_file->largest;
} else {
continue_searching = false;
}
}
}
// vim db/version_set.cc +1324
// Finds minimum file b2=(l2, u2) in level file for which l2 > u1 and
// user_key(l2) = user_key(u1)
FileMetaData* FindSmallestBoundaryFile(
const InternalKeyComparator& icmp,
const std::vector<FileMetaData*>& level_files,
const InternalKey& largest_key) {
const Comparator* user_cmp = icmp.user_comparator();
FileMetaData* smallest_boundary_file = nullptr;
for (size_t i = 0; i < level_files.size(); ++i) {
FileMetaData* f = level_files[i];
if (icmp.Compare(f->smallest, largest_key) > 0 &&
user_cmp->Compare(f->smallest.user_key(), largest_key.user_key()) ==
0) {
if (smallest_boundary_file == nullptr ||
icmp.Compare(f->smallest, smallest_boundary_file->smallest) < 0) {
smallest_boundary_file = f;
}
}
}
return smallest_boundary_file;
}
step2. 获取 level-i+1 合并的 sstbale #
获取 level-i sstable 范围,记作 smllest_key, largest_key
// vim db/version_set.cc +1389
AddBoundaryInputs(icmp_, current_->files_[level], &c->inputs_[0]);
GetRange(c->inputs_[0], &smallest, &largest);
根据该范围调用 GetOverlappingInputs 查找 level-i+1 重叠的文件并追加到 inputs_[1]
// vim db/version_set.cc +1392
current_->GetOverlappingInputs(level + 1, &smallest, &largest,
&c->inputs_[1]);
处理 level-i+1 重叠的边界 sstable
// vim db/version_set.cc +1394
AddBoundaryInputs(icmp_, current_->files_[level + 1], &c->inputs_[1]);
step3. 根据 level-i 和 level-i+1 计算待合并 sstable 的范围 #
GetRange2 输入两个 sstable 文件列表,计算两者的最小、最大 key,记作 all_start,all_limit
// vim db/version_set.cc +1396
// Get entire range covered by compaction
InternalKey all_start, all_limit;
GetRange2(c->inputs_[0], c->inputs_[1], &all_start, &all_limit);
step4. 如果 level-i+1 待合并的 sstable 不为空,尝试扩充 level-i,否则跳到 step5. #
根据 all_start, all_limit 在 level-i 中搜索可以扩大的重叠文件,记作 expand0,同意也要处理 expand0 边界 sstable
// vim db/version_set.cc +1400
// See if we can grow the number of inputs in "level" without
// changing the number of "level+1" files we pick up.
if (!c->inputs_[1].empty()) {
std::vector<FileMetaData*> expanded0;
current_->GetOverlappingInputs(level, &all_start, &all_limit, &expanded0);
AddBoundaryInputs(icmp_, current_->files_[level], &expanded0);
}
计算 level-i, level-i+1 以及 level-i 扩容后的文件大小,如果确实发生了扩容(expanded0.size() > c->inputs_[0].size() 表示文件个数变化)且扩容后的 level-i + level-i+1 文件大小不超过 ExpandedCompactionByteSize (默认为 50MB),则开始处理 level-i 扩容
// vim db/version_set.cc +1406
const int64_t inputs0_size = TotalFileSize(c->inputs_[0]);
const int64_t inputs1_size = TotalFileSize(c->inputs_[1]);
const int64_t expanded0_size = TotalFileSize(expanded0);
if (expanded0.size() > c->inputs_[0].size() &&
inputs1_size + expanded0_size <
ExpandedCompactionByteSizeLimit(options_)) {
获取 level-i 扩容后的 sstable 范围,记作 new_start, new_limit。然后根据该范围在 level-i+1 查找重叠的文件,记作 expand1
// vim db/version_set.cc +1412
InternalKey new_start, new_limit;
GetRange(expanded0, &new_start, &new_limit);
std::vector<FileMetaData*> expanded1;
current_->GetOverlappingInputs(level + 1, &new_start, &new_limit,
&expanded1);
AddBoundaryInputs(icmp_, current_->files_[level + 1], &expanded1);
如果扩容后的 level-i sstable 不影响 level-i+1 的 sstable(也就是新的范围不会导致 level-i+1 文件增多),那么就将 level-i 的 inputs_[0] 替换为 expand0, level-i+1 的 inputs_[1] 替换为 expand1 (但实际上 inputs_[1] 和 expand1 相等),同时更新 level-i 的 sstable 的范围 smallest, largest。最后更新 all_start, all_limit。
// vim db/version_set.cc +1418
if (expanded1.size() == c->inputs_[1].size()) {
Log(options_->info_log,
"Expanding@%d %d+%d (%ld+%ld bytes) to %d+%d (%ld+%ld bytes)\n",
level, int(c->inputs_[0].size()), int(c->inputs_[1].size()),
long(inputs0_size), long(inputs1_size), int(expanded0.size()),
int(expanded1.size()), long(expanded0_size), long(inputs1_size));
smallest = new_start;
largest = new_limit;
c->inputs_[0] = expanded0;
c->inputs_[1] = expanded1;
GetRange2(c->inputs_[0], c->inputs_[1], &all_start, &all_limit);
}
}
step5. 获取 level-i+2 和合并的 sstable 的重叠 sstable 文件 #
根据 all_start, all_limit 计算 level-i+2 的重叠文件,记录在 Compaction 类的 grandparents_ 数据成员中。
// vim db/version_set.cc +1433
// Compute the set of grandparent files that overlap this compaction
// (parent == level+1; grandparent == level+2)
if (level + 2 < config::kNumLevels) {
current_->GetOverlappingInputs(level + 2, &all_start, &all_limit,
&c->grandparents_);
}
grandparents_ 在合并过程中用到。
step6. 更新 level-i 合并的最大 key #
在 compact_pointer_[level] 更新此次合并的 level-i 的最大 key,下一次 compact 将从这个 key 开始。
// vim db/version_set.cc +1440
// Update the place where we will do the next compaction for this level.
// We update this immediately instead of waiting for the VersionEdit
// to be applied so that if the compaction fails, we will try a different
// key range next time.
compact_pointer_[level] = largest.Encode().ToString();
c->edit_.SetCompactPointer(level, largest);
}
下图总结 SetupOtherInputs 的流程
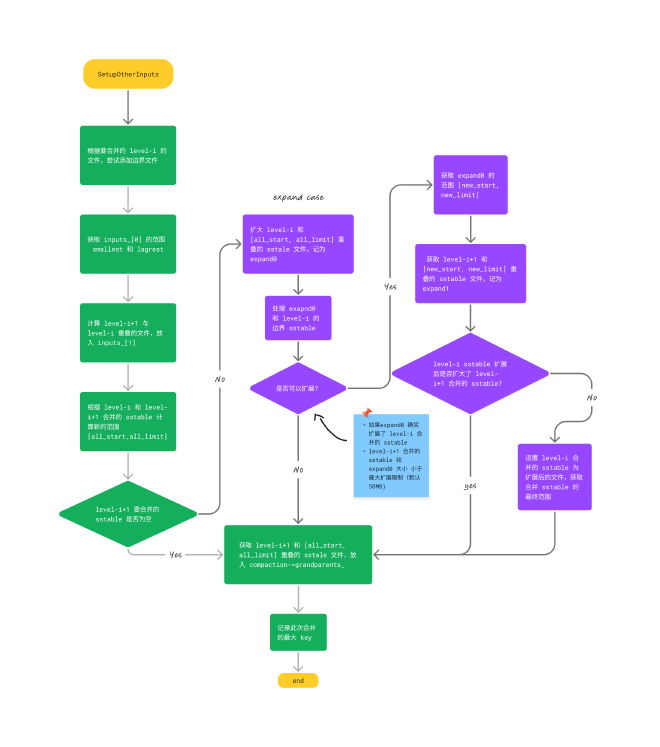
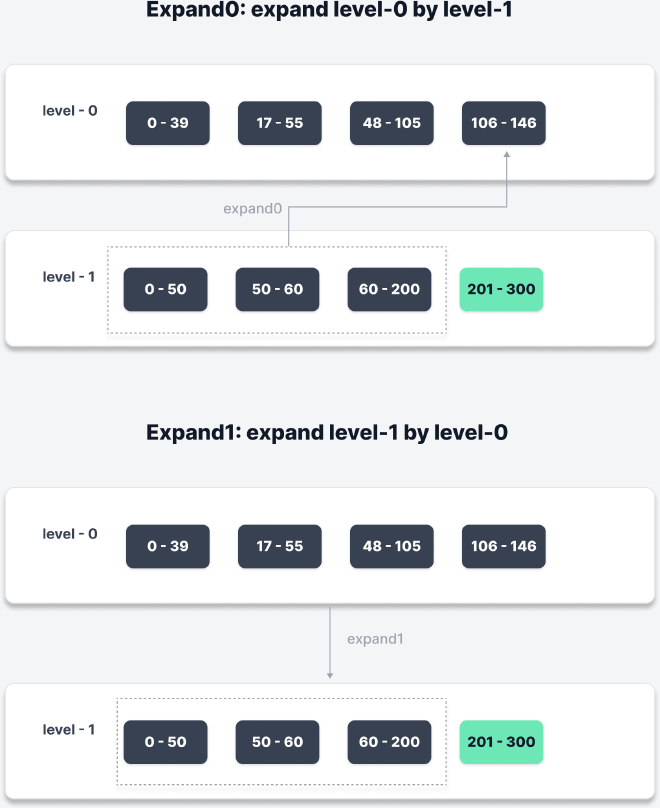
下图中,根据 level-1 的范围,level-0 选择合并的 sstable 扩充了 [106 - 146]。然后,level-0 扩充后的范围为 [0 - 146],新的范围不会影响 level-1,因此这个扩充允许。
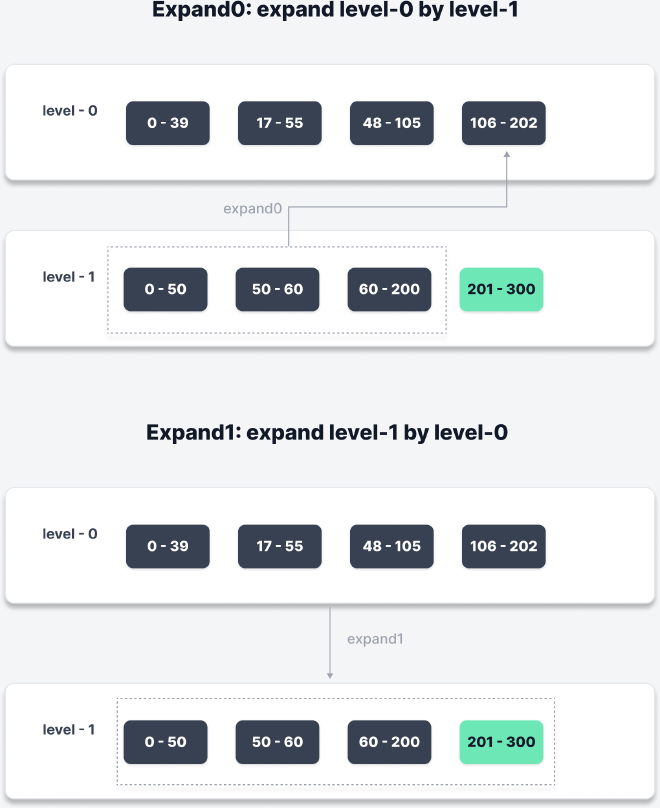
但在下面的图中,level-0 扩充后会导致范围变为 [0 - 202], 从而影响到 level-1,因此这个扩充不会允许。
合并选择的文件 #
前面 PickCompaction 创建 Compaction 类,定义合并时需要的数据成员
// A Compaction encapsulates information about a compaction.
class Compaction {
private:
int level_;
uint64_t max_output_file_size_;
Version* input_version_;
VersionEdit edit_;
std::vector<FileMetaData*> inputs_[2];
std::vector<FileMetaData*> grandparents_;
size_t grandparent_index_;
bool seen_key_;
int64_t overlapped_bytes_;
size_t level_ptrs_[config::kNumLevels];
};
进行合并时有两个 case
- trivial move
- 普通合并
trivial move #
满足3个条件
- level-i (
inputs_[0]) 只有一个文件 - level-i+1 (
inputs_[1]) 不包含任何文件 - level-i+2 与
inputs_[0], inputs_[1]重叠的大小不超过 kMaxGrandParentOverlapBytes (默认20MB,每个文件最大 2MB,10个文件)
// Move the single sstable from level-L to level-L+1 trivially iff
// input0 contains only one file and input1 contains none and total bytes of
// overlapped files in level-L+2 are less than
// kMaxGrandParentOverlapBytes(default 20MB).
bool Compaction::IsTrivialMove() const {
const VersionSet* vset = input_version_->vset_;
// Avoid a move if there is lots of overlapping grandparent data.
// Otherwise, the move could create a parent file that will require
// a very expensive merge later on.
return (num_input_files(0) == 1 && num_input_files(1) == 0 &&
TotalFileSize(grandparents_) <=
MaxGrandParentOverlapBytes(vset->options_));
}
满足 trivial move 时,level-i 的文件直接移动到 level-i+1。具体实现上只需要调整 manifest 的逻辑结构即可。
Status status;
if (c == nullptr) {
// Nothing to do
} else if (!is_manual && c->IsTrivialMove()) {
// Move file to next level
assert(c->num_input_files(0) == 1);
FileMetaData* f = c->input(0, 0);
c->edit()->RemoveFile(c->level(), f->number);
c->edit()->AddFile(c->level() + 1, f->number, f->file_size, f->smallest,
f->largest);
status = versions_->LogAndApply(c->edit(), &mutex_);
if (!status.ok()) {
RecordBackgroundError(status);
}
VersionSet::LevelSummaryStorage tmp;
Log(options_.info_log, "Moved #%lld to level-%d %lld bytes %s: %s\n",
static_cast<unsigned long long>(f->number), c->level() + 1,
static_cast<unsigned long long>(f->file_size),
status.ToString().c_str(), versions_->LevelSummary(&tmp));
}
普通合并 #
使用 CompactionState class 记录合并状态
struct DBImpl::CompactionState {
// Files produced by compaction
struct Output {
uint64_t number;
uint64_t file_size;
InternalKey smallest, largest;
};
Output* current_output() { return &outputs[outputs.size() - 1]; }
explicit CompactionState(Compaction* c)
: compaction(c),
smallest_snapshot(0),
outfile(nullptr),
builder(nullptr),
total_bytes(0) {}
Compaction* const compaction;
// Sequence numbers < smallest_snapshot are not significant since we
// will never have to service a snapshot below smallest_snapshot.
// Therefore if we have seen a sequence number S <= smallest_snapshot,
// we can drop all entries for the same key with sequence numbers < S.
SequenceNumber smallest_snapshot;
std::vector<Output> outputs;
// State kept for output being generated
WritableFile* outfile;
TableBuilder* builder;
uint64_t total_bytes;
};
DoCompactionWork #
DoCompaction 根据选择的文件执行合并,是一个多路归并的逻辑。
step1. 记录最旧的快照 #
合并时需要保证在这个快照之后的数据有效。
// vim db/db_impl.cc +892
Status DBImpl::DoCompactionWork(CompactionState* compact) {
const uint64_t start_micros = env_->NowMicros();
int64_t imm_micros = 0; // Micros spent doing imm_ compactions
Log(options_.info_log, "Compacting %d@%d + %d@%d files",
compact->compaction->num_input_files(0), compact->compaction->level(),
compact->compaction->num_input_files(1),
compact->compaction->level() + 1);
assert(versions_->NumLevelFiles(compact->compaction->level()) > 0);
assert(compact->builder == nullptr);
assert(compact->outfile == nullptr);
if (snapshots_.empty()) {
compact->smallest_snapshot = versions_->LastSequence();
} else {
compact->smallest_snapshot = snapshots_.oldest()->sequence_number();
}
step2. 创建合并迭代器 #
MakeInputIterator 根据 Compaction 创建迭代器
由于 level-0 sstable 重叠,所以 levle-0 每个文件一个迭代器加上 level-1 一个迭代器。其他 level 则创建 2 个迭代器,分别指向 level-i 和 level-i+1。
Iterator* VersionSet::MakeInputIterator(Compaction* c) {
ReadOptions options;
options.verify_checksums = options_->paranoid_checks;
options.fill_cache = false;
// Level-0 files have to be merged together. For other levels,
// we will make a concatenating iterator per level.
// TODO(opt): use concatenating iterator for level-0 if there is no overlap
const int space = (c->level() == 0 ? c->inputs_[0].size() + 1 : 2);
Iterator** list = new Iterator*[space];
int num = 0;
for (int which = 0; which < 2; which++) {
if (!c->inputs_[which].empty()) {
if (c->level() + which == 0) {
const std::vector<FileMetaData*>& files = c->inputs_[which];
for (size_t i = 0; i < files.size(); i++) {
list[num++] = table_cache_->NewIterator(options, files[i]->number,
files[i]->file_size);
}
} else {
// Create concatenating iterator for the files from this level
list[num++] = NewTwoLevelIterator(
new Version::LevelFileNumIterator(icmp_, &c->inputs_[which]),
&GetFileIterator, table_cache_, options);
}
}
}
assert(num <= space);
Iterator* result = NewMergingIterator(&icmp_, list, num);
delete[] list;
return result;
}
然后,使用这些迭代器创建合并迭代器 MergingIterator。
class MergingIterator : public Iterator {
public:
MergingIterator(const Comparator* comparator, Iterator** children, int n)
: comparator_(comparator),
children_(new IteratorWrapper[n]),
n_(n),
current_(nullptr),
direction_(kForward) {
for (int i = 0; i < n; i++) {
children_[i].Set(children[i]);
}
}
MergingIterator::SeekToFirst() 移动到所有的迭代器到开头,并选择迭代器中最小的那个
MergingIterator::Next 对于 Forward 方向,移动最小的迭代器,并再次选择所有迭代器中最小的那个
step3. 合并循环 #
合并通过遍历迭代器完成
- 处理 minor compaction
- 处理 key/value
- 切换输出文件
- 继续下一个 key/value
在 majory compaction 中如果存在 minor compaction,则先进行 minor compaction,因为优先级最高
// vim db/db_impl.cc +912
// Release mutex while we're actually doing the compaction work
mutex_.Unlock();
input->SeekToFirst();
Status status;
ParsedInternalKey ikey;
std::string current_user_key;
bool has_current_user_key = false;
SequenceNumber last_sequence_for_key = kMaxSequenceNumber;
while (input->Valid() && !shutting_down_.load(std::memory_order_acquire)) {
// Prioritize immutable compaction work
if (has_imm_.load(std::memory_order_relaxed)) {
const uint64_t imm_start = env_->NowMicros();
mutex_.Lock();
if (imm_ != nullptr) {
CompactMemTable();
// Wake up MakeRoomForWrite() if necessary.
background_work_finished_signal_.SignalAll();
}
mutex_.Unlock();
imm_micros += (env_->NowMicros() - imm_start);
}
当前文件和 level-i+2 重叠超过最大值(20MB),则切换一个新的文件。
// vim db/db_impl.cc +935
Slice key = input->key();
if (compact->compaction->ShouldStopBefore(key) &&
compact->builder != nullptr) {
status = FinishCompactionOutputFile(compact, input);
if (!status.ok()) {
break;
}
}
ShouldStopBefore 使用 Compaction 中记录的 grandparents_ 计算与当前 key 重叠的大小。
bool Compaction::ShouldStopBefore(const Slice& internal_key) {
const VersionSet* vset = input_version_->vset_;
// Scan to find earliest grandparent file that contains key.
const InternalKeyComparator* icmp = &vset->icmp_;
while (grandparent_index_ < grandparents_.size() &&
icmp->Compare(internal_key,
grandparents_[grandparent_index_]->largest.Encode()) >
0) {
if (seen_key_) {
overlapped_bytes_ += grandparents_[grandparent_index_]->file_size;
}
grandparent_index_++;
}
seen_key_ = true;
if (overlapped_bytes_ > MaxGrandParentOverlapBytes(vset->options_)) {
// Too much overlap for current output; start new output
overlapped_bytes_ = 0;
return true;
} else {
return false;
}
}
处理 key/value
- 相同 key 不同版本的合并,保留 SN 最大的那个
- 标记删除的 key 回收
- 照顾快照
合并 key 条件
-
多个 (user_key, SN) 都相等,保留第一个,后续的 key 如果没有被之前的快照使用,就可以丢弃
-
多个 user_key 相等,SN 不等,后一个覆盖前一个(sstable 是按照 SN 从小到大排序)
回收 key 条件
- key 被标记删除
- key 没有被活跃的快照使用
- key 在 level-i + 2 的文件范围中
// vim db/db_impl.cc +945
bool drop = false;
if (!ParseInternalKey(key, &ikey)) {
// Do not hide error keys
current_user_key.clear();
has_current_user_key = false;
last_sequence_for_key = kMaxSequenceNumber;
} else {
if (!has_current_user_key ||
user_comparator()->Compare(ikey.user_key, Slice(current_user_key)) !=
0) {
// First occurrence of this user key
current_user_key.assign(ikey.user_key.data(), ikey.user_key.size());
has_current_user_key = true;
last_sequence_for_key = kMaxSequenceNumber;
}
if (last_sequence_for_key <= compact->smallest_snapshot) {
// Hidden by an newer entry for same user key
drop = true; // (A)
} else if (ikey.type == kTypeDeletion &&
ikey.sequence <= compact->smallest_snapshot &&
compact->compaction->IsBaseLevelForKey(ikey.user_key)) {
// For this user key:
// (1) there is no data in higher levels
// (2) data in lower levels will have larger sequence numbers
// (3) data in layers that are being compacted here and have
// smaller sequence numbers will be dropped in the next
// few iterations of this loop (by rule (A) above).
// Therefore this deletion marker is obsolete and can be dropped.
drop = true;
}
last_sequence_for_key = ikey.sequence;
}
-
current_user_key记录了上一次循环遇到的 key,如果两个 key 不相等(可能 user_key 相等,但 SN 不等),则更新current_user_key,记录last_sequence_for_key为最大值。如果 key 相等,last_sequence_for_key 记录了 key 的 SN。 -
last_sequence_for_key <= compact->smallest_snapshot测试条件生效时说明前面遇到了相同的 key,并且第一次遇到的会写入合并后的文件,因此可以丢弃 -
IsBaseLevelForKey查找 key 是否出现在 level-i+2 开始往后的层级中// vim db/version_set.cc +1517 bool Compaction::IsBaseLevelForKey(const Slice& user_key) { // Maybe use binary search to find right entry instead of linear search? const Comparator* user_cmp = input_version_->vset_->icmp_.user_comparator(); for (int lvl = level_ + 2; lvl < config::kNumLevels; lvl++) { const std::vector<FileMetaData*>& files = input_version_->files_[lvl]; while (level_ptrs_[lvl] < files.size()) { FileMetaData* f = files[level_ptrs_[lvl]]; if (user_cmp->Compare(user_key, f->largest.user_key()) <= 0) { // We've advanced far enough if (user_cmp->Compare(user_key, f->smallest.user_key()) >= 0) { // Key falls in this file's range, so definitely not base level return false; } break; } level_ptrs_[lvl]++; } } return true; }
通过 builder 写入 key/value,如果新的文件超过最大限制则切换文件。继续处理下一个 key/value
// vim db/db_impl.cc +989
if (!drop) {
// Open output file if necessary
if (compact->builder == nullptr) {
status = OpenCompactionOutputFile(compact);
if (!status.ok()) {
break;
}
}
if (compact->builder->NumEntries() == 0) {
compact->current_output()->smallest.DecodeFrom(key);
}
compact->current_output()->largest.DecodeFrom(key);
compact->builder->Add(key, input->value());
// Close output file if it is big enough
if (compact->builder->FileSize() >=
compact->compaction->MaxOutputFileSize()) {
status = FinishCompactionOutputFile(compact, input);
if (!status.ok()) {
break;
}
}
}
input->Next();
}
写入最后一个文件
// vim db/db_impl.cc +1016
if (status.ok() && shutting_down_.load(std::memory_order_acquire)) {
status = Status::IOError("Deleting DB during compaction");
}
if (status.ok() && compact->builder != nullptr) {
status = FinishCompactionOutputFile(compact, input);
}
if (status.ok()) {
status = input->status();
}
delete input;
input = nullptr;
step4. 记录合并状态 #
// vim db/db_impl.cc +1028
CompactionStats stats;
stats.micros = env_->NowMicros() - start_micros - imm_micros;
for (int which = 0; which < 2; which++) {
for (int i = 0; i < compact->compaction->num_input_files(which); i++) {
stats.bytes_read += compact->compaction->input(which, i)->file_size;
}
}
for (size_t i = 0; i < compact->outputs.size(); i++) {
stats.bytes_written += compact->outputs[i].file_size;
}
mutex_.Lock();
stats_[compact->compaction->level() + 1].Add(stats);
step5. 更新 manifest #
// vim db/db_impl.cc +1042
if (status.ok()) {
status = InstallCompactionResults(compact);
}
if (!status.ok()) {
RecordBackgroundError(status);
}
VersionSet::LevelSummaryStorage tmp;
Log(options_.info_log, "compacted to: %s", versions_->LevelSummary(&tmp));
return status;
}
删除无效文件 #
// vim db/db_impl.cc +749
CompactionState* compact = new CompactionState(c);
status = DoCompactionWork(compact);
if (!status.ok()) {
RecordBackgroundError(status);
}
CleanupCompaction(compact);
c->ReleaseInputs();
RemoveObsoleteFiles();
}
delete c;