Rust Allocator Designs #
This post explains how to implement heap allocators from scratch. It presents and discusses different allocator designs, including bump allocation, linked list allocation, and fixed-size block allocation. For each of the three designs, we will create a basic implementation that can be used for our kernel.
This blog is openly developed on
GitHub. If you have any problems or questions, please open an issue there. You can also leave comments
at the bottom. The complete source code for this post can be found in the [post-11](https://github.com/phil-opp/blog_os/tree/post-11) branch.
Introduction #
In the
previous post we added basic support for heap allocations to our kernel. For that, we
created a new memory region in the page tables and
used the linked_list_allocator crate to manage that memory. While we have a working heap now, we left most of the work to the allocator crate without trying to understand how it works.
In this post, we will show how to create our own heap allocator from scratch instead of relying on an existing allocator crate. We will discuss different allocator designs, including a simplistic bump allocator and a basic fixed-size block allocator , and use this knowledge to implement an allocator with improved performance (compared to the linked_list_allocator crate).
Design Goals #
The responsibility of an allocator is to manage the available heap memory. It needs to return unused memory on alloc calls and keep track of memory freed by dealloc so that it can be reused again. Most importantly, it must never hand out memory that is already in use somewhere else because this would cause undefined behavior.
Apart from correctness, there are many secondary design goals. For example, the allocator should effectively utilize the available memory and keep fragmentation low. Furthermore, it should work well for concurrent applications and scale to any number of processors. For maximal performance, it could even optimize the memory layout with respect to the CPU caches to improve cache locality and avoid false sharing.
These requirements can make good allocators very complex. For example, jemalloc has over 30.000 lines of code. This complexity is often undesired in kernel code where a single bug can lead to severe security vulnerabilities. Fortunately, the allocation patterns of kernel code are often much simpler compared to userspace code, so that relatively simple allocator designs often suffice.
In the following we present three possible kernel allocator designs and explain their advantages and drawbacks.
Bump Allocator #
The most simple allocator design is a bump allocator (also known as stack allocator). It allocates memory linearly and only keeps track of the number of allocated bytes and the number of allocations. It is only useful in very specific use cases because it has a severe limitation: it can only free all memory at once.
Idea #
The idea behind a bump allocator is to linearly allocate memory by increasing (“bumping”) a next variable, which points at the beginning of the unused memory. At the beginning, next is equal to the start address of the heap. On each allocation, next is increased by the allocation so that it always points to the boundary between used and unused memory:
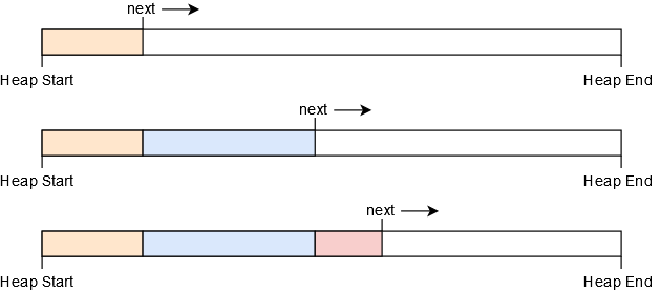
The next pointer only moves in a single direction and thus never hands out the same memory region twice. When it reaches the end of the heap, no more memory can be allocated, resulting in an out-of-memory error on the next allocation.
A bump allocator is often implemented with an allocation counter, which is increased by 1 on each alloc call and decreased by 1 on each dealloc call. When the allocation counter reaches zero it means that all allocations on the heap were deallocated. In this case, the next pointer can be reset to the start address of the heap, so that the complete heap memory is available to allocations again.
Implementation #
We start our implementation by declaring a new allocator::bump submodule:
// in src/allocator.rs
pub mod bump;
The content of the submodule lives in a new src/allocator/bump.rs file, which we create with the following content:
// in src/allocator/bump.rs
pub struct BumpAllocator {
heap_start: usize,
heap_end: usize,
next: usize,
allocations: usize,
}
impl BumpAllocator {
/// Creates a new empty bump allocator.
pub const fn new() -> Self {
BumpAllocator {
heap_start: 0,
heap_end: 0,
next: 0,
allocations: 0,
}
}
/// Initializes the bump allocator with the given heap bounds.
///
/// This method is unsafe because the caller must ensure that the given
/// memory range is unused. Also, this method must be called only once.
pub unsafe fn init(&mut self, heap_start: usize, heap_size: usize) {
self.heap_start = heap_start;
self.heap_end = heap_start + heap_size;
self.next = heap_start;
}
}
The heap_start and heap_end fields keep track of the lower and upper bound of the heap memory region. The caller needs to ensure that these addresses are valid, otherwise the allocator would return invalid memory. For this reason, the init function needs to be unsafe to call.
The purpose of the next field is to always point to the first unused byte of the heap, i.e. the start address of the next allocation. It is set to heap_start in the init function because at the beginning the complete heap is unused. On each allocation, this field will be increased by the allocation size (“bumped”) to ensure that we don’t return the same memory region twice.
We chose to create a separate init function instead of performing the initialization directly in new in order to keep the interface identical to the allocator provided by thelinked_list_allocator crate. This way, the allocators can be switched without additional code changes.
Implementing GlobalAlloc #
As
explained in the previous post, all heap allocators need to implement the [GlobalAlloc](https://doc.rust-lang.org/alloc/alloc/trait.GlobalAlloc.html) trait, which is defined like this:
pub unsafe trait GlobalAlloc {
unsafe fn alloc(&self, layout: Layout) -> *mut u8;
unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout);
unsafe fn alloc_zeroed(&self, layout: Layout) -> *mut u8 { ... }
unsafe fn realloc(
&self,
ptr: *mut u8,
layout: Layout,
new_size: usize
) -> *mut u8 { ... }
}
Only the alloc and dealloc methods are required, the other two methods have default implementations and can be omitted.
First Implementation Attempt #
Let’s try to implement the alloc method for our BumpAllocator:
// in src/allocator/bump.rs
use alloc::alloc::{GlobalAlloc, Layout};
unsafe impl GlobalAlloc for BumpAllocator {
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
// TODO alignment and bounds check
let alloc_start = self.next;
self.next = alloc_start + layout.size();
self.allocations += 1;
alloc_start as *mut u8
}
unsafe fn dealloc(&self, _ptr: *mut u8, _layout: Layout) {
todo!();
}
}
First, we use the next field as the start address for our allocation. Then we update the next field to point at the end address of the allocation, which is the next unused address on the heap. Before returning the start address of the allocation as a *mut u8 pointer, we increase the allocations counter by 1.
Note that we don’t perform any bounds checks or alignment adjustments, so this implementation is not safe yet. This does not matter much because it fails to compile anyway with the following error:
error[E0594]: cannot assign to `self.next` which is behind a `&` reference
--> src/allocator/bump.rs:29:9
|
29 | self.next = alloc_start + layout.size();
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be written
(The same error also occurs for the self.allocations += 1 line. We omitted it here for brevity.)
The error occurs because the [alloc](https://doc.rust-lang.org/alloc/alloc/trait.GlobalAlloc.html#tymethod.alloc) and [dealloc](https://doc.rust-lang.org/alloc/alloc/trait.GlobalAlloc.html#tymethod.dealloc) methods of the GlobalAlloc trait only operate on an immutable &self reference, so updating the next and allocations fields is not possible. This is problematic because updating next on every allocation is the essential principle of a bump allocator.
GlobalAlloc and Mutability #
Before we look at a possible solution to this mutability problem, let’s try to understand why the GlobalAlloc trait methods are defined with &self arguments: As we saw
in the previous post, the global heap allocator is defined by adding the #[global_allocator] attribute to a static that implements the GlobalAlloc trait. Static variables are immutable in Rust, so there is no way to call a method that takes &mut self on the static allocator. For this reason, all the methods of GlobalAlloc only take an immutable &self reference.
Fortunately there is a way how to get a &mut self reference from a &self reference: We can use synchronized
interior mutability by wrapping the allocator in a [spin::Mutex](https://docs.rs/spin/0.5.0/spin/struct.Mutex.html) spinlock. This type provides a lock method that performs
mutual exclusion and thus safely turns a &self reference to a &mut self reference. We already used the wrapper type multiple times in our kernel, for example for the
VGA text buffer.
A Locked Wrapper Type #
With the help of the spin::Mutex wrapper type we can implement the GlobalAlloc trait for our bump allocator. The trick is to implement the trait not for the BumpAllocator directly, but for the wrapped spin::Mutex<BumpAllocator> type:
unsafe impl GlobalAlloc for spin::Mutex<BumpAllocator> {…}
Unfortunately, this still doesn’t work because the Rust compiler does not permit trait implementations for types defined in other crates:
error[E0117]: only traits defined in the current crate can be implemented for arbitrary types
--> src/allocator/bump.rs:28:1
|
28 | unsafe impl GlobalAlloc for spin::Mutex<BumpAllocator> {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^--------------------------
| | |
| | `spin::mutex::Mutex` is not defined in the current crate
| impl doesn't use only types from inside the current crate
|
= note: define and implement a trait or new type instead
To fix this, we need to create our own wrapper type around spin::Mutex:
// in src/allocator.rs
/// A wrapper around spin::Mutex to permit trait implementations.
pub struct Locked<A> {
inner: spin::Mutex<A>,
}
impl<A> Locked<A> {
pub const fn new(inner: A) -> Self {
Locked {
inner: spin::Mutex::new(inner),
}
}
pub fn lock(&self) -> spin::MutexGuard<A> {
self.inner.lock()
}
}
The type is a generic wrapper around a spin::Mutex<A>. It imposes no restrictions on the wrapped type A, so it can be used to wrap all kinds of types, not just allocators. It provides a simple new constructor function that wraps a given value. For convenience, it also provides a lock function that calls lock on the wrapped Mutex. Since the Locked type is general enough to be useful for other allocator implementations too, we put it in the parent allocator module.
Implementation for Locked
#
The Locked type is defined in our own crate (in contrast to spin::Mutex), so we can use it to implement GlobalAlloc for our bump allocator. The full implementation looks like this:
// in src/allocator/bump.rs
use super::{align_up, Locked};
use alloc::alloc::{GlobalAlloc, Layout};
use core::ptr;
unsafe impl GlobalAlloc for Locked<BumpAllocator> {
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
let mut bump = self.lock(); // get a mutable reference
let alloc_start = align_up(bump.next, layout.align());
let alloc_end = match alloc_start.checked_add(layout.size()) {
Some(end) => end,
None => return ptr::null_mut(),
};
if alloc_end > bump.heap_end {
ptr::null_mut() // out of memory
} else {
bump.next = alloc_end;
bump.allocations += 1;
alloc_start as *mut u8
}
}
unsafe fn dealloc(&self, _ptr: *mut u8, _layout: Layout) {
let mut bump = self.lock(); // get a mutable reference
bump.allocations -= 1;
if bump.allocations == 0 {
bump.next = bump.heap_start;
}
}
}
The first step for both alloc and dealloc is to call the [Mutex::lock](https://docs.rs/spin/0.5.0/spin/struct.Mutex.html#method.lock) method through the inner field to get a mutable reference to the wrapped allocator type. The instance remains locked until the end of the method, so that no data race can occur in multithreaded contexts (we will add threading support soon).
Compared to the previous prototype, the alloc implementation now respects alignment requirements and performs a bounds check to ensure that the allocations stay inside the heap memory region. The first step is to round up the next address to the alignment specified by the Layout argument. The code for the align_up function is shown in a moment. We then add the requested allocation size to alloc_start to get the end address of the allocation. To prevent integer overflow on large allocations, we use the [checked_add](https://doc.rust-lang.org/std/primitive.usize.html#method.checked_add) method. If an overflow occurs or if the resulting end address of the allocation is larger than the end address of the heap, we return a null pointer to signal an out-of-memory situation. Otherwise, we update the next address and increase the allocations counter by 1 like before. Finally, we return the alloc_start address converted to a *mut u8 pointer.
The dealloc function ignores the given pointer and Layout arguments. Instead, it just decreases the allocations counter. If the counter reaches 0 again, it means that all allocations were freed again. In this case, it resets the next address to the heap_start address to make the complete heap memory available again.
Address Alignment #
The align_up function is general enough that we can put it into the parent allocator module. A basic implementation looks like this:
// in src/allocator.rs
/// Align the given address `addr` upwards to alignment `align`.
fn align_up(addr: usize, align: usize) -> usize {
let remainder = addr % align;
if remainder == 0 {
addr // addr already aligned
} else {
addr - remainder + align
}
}
The function first computes the
remainder of the division of addr by align. If the remainder is 0, the address is already aligned with the given alignment. Otherwise, we align the address by subtracting the remainder (so that the new remainder is 0) and then adding the alignment (so that the address does not become smaller than the original address).
Note that this isn’t the most efficient way to implement this function. A much faster implementation looks like this:
/// Align the given address `addr` upwards to alignment `align`.
///
/// Requires that `align` is a power of two.
fn align_up(addr: usize, align: usize) -> usize {
(addr + align - 1) & !(align - 1)
}
This method utilizes that the GlobalAlloc trait guarantees that align is always a power of two. This makes it possible to create a
bitmask to align the address in a very efficient way. To understand how it works, let’s go through it step by step starting on the right side:
- Since
alignis a power of two, its binary representation has only a single bit set (e.g.0b000100000). This means thatalign - 1has all the lower bits set (e.g.0b00011111). - By creating the
bitwise
NOTthrough the!operator, we get a number that has all the bits set except for the bits lower thanalign(e.g.0b…111111111100000). - By performing a
bitwise
ANDon an address and!(align - 1), we align the address downwards. This works by clearing all the bits that are lower thanalign. - Since we want to align upwards instead of downwards, we increase the
addrbyalign - 1before performing the bitwiseAND. This way, already aligned addresses remain the same while non-aligned addresses are rounded to the next alignment boundary.
Which variant you choose it up to you. Both compute the same result, only using different methods.
Using It #
To use the bump allocator instead of the linked_list_allocator crate, we need to update the ALLOCATOR static in allocator.rs:
// in src/allocator.rs
use bump::BumpAllocator;
#[global_allocator]
static ALLOCATOR: Locked<BumpAllocator> = Locked::new(BumpAllocator::new());
Here it becomes important that we declared BumpAllocator::new and Locked::new as [const functions](
https://doc.rust-lang.org/reference/items/functions.html#const-functions). If they were normal functions, a compilation error would occur because the initialization expression of a static must evaluable at compile time.
Here it becomes important that we declared BumpAllocator::new and Locked::new as [const functions](
https://doc.rust-lang.org/reference/items/functions.html#const-functions). If they were normal functions, a compilation error would occur because the initialization expression of a static must evaluable at compile time.
We don’t need to change the ALLOCATOR.lock().init(HEAP_START, HEAP_SIZE) call in our init_heap function because the bump allocator provides the same interface as the allocator provided by the linked_list_allocator.
Now our kernel uses our bump allocator! Everything should still work, including the [heap_allocation tests](
https://os.phil-opp.com/heap-allocation/#adding-a-test) that we created in the previous post:
> cargo test --test heap_allocation
[…]
Running 3 tests
simple_allocation... [ok]
large_vec... [ok]
many_boxes... [ok]
Discussion #
The big advantage of bump allocation is that it’s very fast. Compared to other allocator designs (see below) that need to actively look for a fitting memory block and perform various bookkeeping tasks on alloc and dealloc, a bump allocator
can be optimized to just a few assembly instructions. This makes bump allocators useful for optimizing the allocation performance, for example when creating a
virtual DOM library.
While a bump allocator is seldom used as the global allocator, the principle of bump allocation is often applied in form of
arena allocation, which basically batches individual allocations together to improve performance. An example for an arena allocator for Rust is the [toolshed](https://docs.rs/toolshed/0.8.1/toolshed/index.html) crate.
The Drawback of Bump Allocator #
The main limitation of a bump allocator is that it can only reuse deallocated memory after all allocations have been freed. This means that a single long-lived allocation suffices to prevent memory reuse. We can see this when we add a variation of the many_boxes test:
// in tests/heap_allocation.rs
#[test_case]
fn many_boxes_long_lived() {
let long_lived = Box::new(1); // new
for i in 0..HEAP_SIZE {
let x = Box::new(i);
assert_eq!(*x, i);
}
assert_eq!(*long_lived, 1); // new
}
Like the many_boxes test, this test creates a large number of allocations to provoke an out-of-memory failure if the allocator does not reuse freed memory. Additionally, the test creates a long_lived allocation,which lives for the whole loop execution.
When we try run our new test, we see that it indeed fails:
> cargo test --test heap_allocation
Running 4 tests
simple_allocation... [ok]
large_vec... [ok]
many_boxes... [ok]
many_boxes_long_lived... [failed]
Error: panicked at 'allocation error: Layout { size_: 8, align_: 8 }', src/lib.rs:86:5
Let’s try to understand why this failure occurs in detail: First, the long_lived allocation is created at the start of the heap, thereby increasing the allocations counter by 1. For each iteration of the loop, a short lived allocation is created and directly freed again before the next iteration starts. This means that the allocations counter is temporarily increased to 2 at the beginning of an iteration and decreased to 1 at the end of it. The problem now is that the bump allocator can only reuse memory when all allocations have been freed, i.e. the allocations counter falls to 0. Since this doesn’t happen before the end of the loop, each loop iteration allocates a new region of memory, leading to an out-of-memory error after a number of iterations.
Fixing the Test? #
There are two potential tricks that we could utilize to fix the test for our bump allocator:
- We could update
deallocto check whether the freed allocation was the last allocation returned byallocby comparing its end address with thenextpointer. In case they’re equal, we can safely resetnextback to the start address of the freed allocation. This way, each loop iteration reuses the same memory block. - We could add an
alloc_backmethod that allocates memory from the end of the heap using an additionalnext_backfield. Then we could manually use this allocation method for all long-lived allocations, thereby separating short-lived and long-lived allocations on the heap. Note that this separation only works if it’s clear beforehand how long each allocation lives. Another drawback of this approach is that manually performing allocations is cumbersome and potentially unsafe.
While both of these approaches work to fix the test, they are no general solution since they are only able to reuse memory in very specific cases. The question is: Is there a general solution that reuses all freed memory?
Reusing All Freed Memory? #
As we learned in the previous post, allocations can live arbitrarily long and can be freed in an arbitrary order. This means that we need to keep track of a potentially unbounded number of non-continuous, unused memory regions, as illustrated by the following example:

The graphic shows the heap over the course of time. At the beginning, the complete heap is unused and the next address is equal to heap_start (line 1). Then the first allocation occurs (line 2). In line 3, a second memory block is allocated and the first allocation is freed. Many more allocations are added in line 4. Half of them are very short-lived and already get freed in line 5, where also another new allocation is added.
Line 5 shows the fundamental problem: We have five unused memory regions with different sizes in total, but the next pointer can only point to the beginning of the last region. While we could store the start addresses and sizes of the other unused memory regions in an array of size 4 for this example, this isn’t a general solution since we could easily create an example with 8, 16, or 1000 unused memory regions.
Normally when we have a potentially unbounded number of items, we can just use a heap allocated collection. This isn’t really possible in our case, since the heap allocator can’t depend on itself (it would cause endless recursion or deadlocks). So we need to find a different solution.